1. Don't Stop Pretraining: Adapt Language Models to Domains and Tasks (DAPT, TAPT)
Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don't stop pretraining: adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
https://arxiv.org/abs/2004.10964
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
Language models pretrained on text from a wide variety of sources form the foundation of today's NLP. In light of the success of these broad-coverage models, we investigate whether it is still helpful to tailor a pretrained model to the domain of a target
arxiv.org
1.1. Introduction

- RoBERTa와 같은 모델은 160기가가 넘는 큰 데이터에 대해 학습을 진행했지만, 이렇게 큰 데이터도 모든 domain을 포괄하는 것은 불가능
- 그렇다면 domain specific한 곳에 대해서도 일반화된 성능을 유지할 수 있는가와 혹은 domain 관련 데이터로 추가적 학습을 시켜주는 것이 모델 성능 개선에 도움이 될 것인가에 대해 연구진들은 의문을 품었음
- 기존에 연구도 있었으나 대량의 데이터로 학습한 것을 다시 추가적으로 학습한 것에 대한 연구는 존재하지 않음
- 결과적으로 데이터가 많냐 적냐에 상관없이 DAPT는 전반적으로 성능의 개선을 야기
- 이와 함께 task와 더 관련이 높은 데이터로 학습을 시켜주는 TAPT를 진행했을 때 더 높은 성능 개선
- DAPT, TAPT 두 가지를 모두 사용했을 때에는 더 높은 성능 개선
- 최종적으로 연구진들은 사람들이 선별한 데이터를 통해 추가적인 pretrain을 시켰을 때에 높은 성능 개선을 보였음. 하지만 이는 쉽지 않기 때문에 이를 만들 수 있는 간단한 방식을 고안
결과적으로 연구진이 진행한 것을 요약하면 다음과 같다
- DAPT, TAPT를 통해 데이터량에 상관 없이 성능을 높였다는 것
- 해당 방식을 loss를 관찰하며 면밀히 연구했다는 점
- 이러한 데이터셋을 만들기 위해 자동화된 시스템을 고안했다는 점
1.2. Domain-Adaptive Pretraining
- domain에 관련된 데이터를 더 구해 추가적으로 pretrain
- BioMed, CS, News, Reviews 네 가지 카테고리에 대해 진행
1.2.1. Analyzing Domain Simiraity
- DAPT를 진행하기 이전에 RoBERTa의 pretrain domain과 target domain간의 유사도를 정량화
- 이때에 각 도메인에서 가장 빈번한 unigrams 10000개(stopwords 제외)를 포함한 도메인 사전을 만들었음
- 그후 reviews 데이터셋은 데이터들의 길이가 짧기 때문에 150K개의 문서를 구했고 다른 세 개의 domain에서는 50K개의 문서를 사용
- 또한 기존 RoBERTa에서 사용된 말뭉치는 공개되지 않았기 때문에 사전학습 말뭉치와 유사한 sources에서 50K개의 문서를 직접 샘플링

- 위의 그림은 단어간의 중복을 나타냄
- PT는 기존 사전학습 말뭉치와 유사한 것을 구한 말뭉치. 이를 통해 PT는 News와 가장 유사하며 CS와 가장 낮은 유사도
- 이들을 보았을 때 기본 모델이 PT와 가장 유사한 것에서 높은 성능을 CS에 대해서 낮은 성능을 보일 것을 예측할 수 있음
1.2.2. Experiments

- 기본 RoBERTa 모델은 ROBA, not DAPT는 관련도가 가장 적은 데이터셋으로 DAPT를 진행했을 때의 성능
- 거의 모든 경우에 대해서 DAPT를 진행했을 때 성능의 개선이 있음
- News에 대해서만 성능 개선이 없었는데 이는 기존 pretrain 데이터셋이 news와 거의 유사했기 때문으로 보임
- not DAPT를 통해 그저 데이터를 늘려주는 것이 효과를 발생시키는 것인지에 대한 연구를 진행
- 표에서 볼 수 있던 것처럼 데이터를 그저 늘려주는 것은 오히려 역효과를 발생
- 즉, 데이터를 아무런 고려 없이 DAPT로 사용하는 것은 위험할 수 있다는 것
- 하지만 몇몇 case에 대해서는 성능 개선이 있는 것으로 보아 완전히 의미 없는 행위로 치부하기는 어려웠음
1.3. Task-Adaptive Pretraining
- 동일한 domain에서도 task에 따라 데이터 분포가 달라질 수 있음
- 가령 동일한 뉴스 데이터라 하더라도 가짜뉴스 판별 태스크와 뉴스 카테고리 분류 태스크는 전혀 다른 데이터 분포를 가지게 될 것
- 다운스트림 태스크를 수행하기 위해 수집한 데이터를 이용하여 진행하는 사전학습을 TAPT라 정의
- TAPT는 task에 매우 적합한 데이터만 선별해야하는 특성 상 DAPT보다 훨씬 데이터셋의 크기는 작지만, 태스크와 매우 밀접한 분포를 가지는 데이터라는 점에서 일종의 trade-off 관계를 가짐
- 또한 데이터셋이 작다보니 연산량이 적다는 것이 장점
1.3.1. Experiments
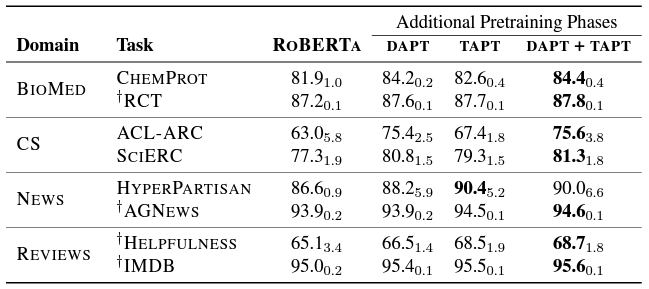
- TAPT는 일관되게 RoBERTA의 성능을 뛰어넘었음
- 더 나아가 성능 개선이 뚜렷하지 않던 News 도메인에서도 TAPT의 성능이 더 나았음
- 특히 주목할 점은, TAPT와 DAPT간의 차이인데 DAPT에 더 data가 많이 들어감에도 불구하고 TAPT는 몇몇의 task에 대해 DAPT의 성능을 넘어서는 모습을 보임
- DAPT+TAPT는 모든 task에서 가장 좋은 성능을 보임
- 논문에서는 순서를 반대로 하는 것, TAPT후에 DAPT를 적용하는 것은 task 관련 말뭉치(더 높은 관련성이 있는 말뭉치)의 심각한 망각을 유발할 것이라고 말하며 성능 결과 또한 낮게 나왔음
1.4. Augmentation for TAPT
TAPT가 DAPT만큼이나 혹은 그 이상 효과가 좋다면, TAPT를 위해 태스크 데이터를 좀 더 확보할 수 없을까? 이 논문에서는 두 가지 방법을 제안하고 있다.
1.4.1 Human Curated-TAPT

- 사람이 직접 annotation하는 것. 즉 해당 도메인의 데이터 중에 태스크와 직접적으로 관련이 있는 데이터를 사람이 선별하여 이 데이터를 이용하여 TAPT를 진행하는 것
- 데이터가 많을수록, 태스크 분포와 가까울수록 성능이 점차 높아지는 모습을 보여주고 있음
1. 4. 2. Automated Data Selection for TAPT

- 하지만 실제 상황에서는 추가적으로 annotation을 진행하는 것이 쉬운 일이 아님
- 도메인이 일치하는 대량의 데이터셋을 구하는 것이 가능하다는 보장도 없고, DAPT를 수행하기 위한 컴퓨팅 자원 역시 만만치 않음
- 이때 자동화된 방법으로 태스크 데이터와 분포가 가까운 레이블이 없는 데이터를 선별할 수 있는 방법 제안
- 도메인 데이터와 태스크 데이터를 모두 하나의 임베딩 공간에 넣고, 여기서 태스크 데이터와 가까운 도메인 데이터를 TAPT에 추가적으로 사용하는 것
- 이때 임베딩은 VAMPIRE(Gururangan et al., 2019)이라 하는 빠르고 단순한 BoW 방식의 LM 모델을 사용
- kNN-TAPT가 TAPT의 모든 경우에 대해 가장 높은 성능을 보임
- 즉, KNN을 사용하는 방법이 연관성을 어느정도 확보해줄 수 있음
- RAND-TAPT는 오히려 TAPT보다 성능이 낮음
- 하지만 한 표준편차내의 random 선택은 몇몇의 데이터셋에서 성능의 향상
- k를 증가시킬수록 kNN-TAPT의 성능은 점점 증가했고 DAPT의 성능까지 가까이 감
2. ODQA Reader Experiment - 외부데이터셋 추가, TAPT
- KorQuAD 1.0: 1,550개의 위키피디아 문서에 대해서 10,649 건의하위 문서들과 크라우드소싱을 통해 제작한 63,952 개의 질의응답 쌍 데이터 사용
- AI Hub 일반상식: 한국어 위키백과내 주요 문서 15만개에 포함된 지식을 추출하여 객체(entity), 속성(attribute), 값(value)을 갖는 트리플 형식의 데이터 75만개를 구축. WIKI 본문내용과 관련한 질문과 질문에 대응되는 WIKI 본문 내의 정답 쌍 데이터 사용
실험 과정
1. 원본 데이터 + 외부 데이터셋 추가 finetuning
→ 오히려 성능이 떨어짐
2. 외부 데이터셋 pre-training epoch early stopping 까지, 원본 데이터 finetuning
→ 오히려 성능이 떨어짐. 외부 데이터셋 대략 12만개 원본 데이터 대략 4천 개, 약 30배 차이. 너무 큰 데이터의 양 차이가 성능 하락을 만든 것으로 추론
3. 외부 데이터셋 pre-training 1 epoch, 원본 데이터 finetuning

→ 원본 데이터 대비 EM 2.83, F1 5.26 성능향상
'Projects' 카테고리의 다른 글
| [Open-domain question answering(ODQA)] 4. Reader Experiment - Curriculum Learning (0) | 2023.01.08 |
|---|---|
| [Open-domain question answering(ODQA)] 3. Retrieval Experiment - ElasticSearch(엘라스틱 서치) (0) | 2023.01.08 |
| [Open-domain question answering(ODQA)] 2. EDA, Pytorch Lightning Refactoring (0) | 2023.01.08 |
| [Open-domain question answering(ODQA)] 1. 프로젝트 개요 (2) | 2023.01.08 |
| NLP 자동차 주제 데이터 제작 프로젝트 (0) | 2022.12.28 |



