
1. 프로젝트 개요
💡 [NLP] 문장 내 개체간 관계 추출
문장의 단어(Entitiy)에 대한 속성관 관계를 예측하는 인공지능 만들기
문장 속에서 단어간에 관계성을 파악하는 것은 의미나 의도를 해석함에 있어서 많은 도움을 줍니다.
그림의 예시와 같이 요약된 정보를 사용해 QA 시스템 구축과 활용이 가능하며, 이외에도 요약된 언어 정보를 바탕으로 효율적인 시스템 및 서비스 구성이 가능합니다.
- 관계 추출(Relation Extraction)은 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제입니다. 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변하기, 요약과 같은 자연어처리 응용 프로그램에서 중요합니다. 비구조적인 자연어 문장에서 구조적인 triple을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있습니다.
TimeLine

협업 방식
Notion
- Team Notion에 실험 결과 기록
- Kanban Board로 담당자 및 진행 상황 공유

Git
- Git Commit Message Convention
- feat : 새로운 기능 추가
- fix : 버그 수정
- docs : 문서 수정
- style : 코드 포맷팅, 세미콜론 누락, 코드 변경이 없는 경우
- refactor : 코드 리펙토링
- test : 테스트 코드, 리펙토링 테스트 코드 추가
- chore : 빌드 업무 수정, 패키지 매니저 수정
- <참고> 🔗 Conventional Commits
- Git flow
- master : 제품으로 출시될 수 있는 브랜치
- develop : 다음 출시 버전을 개발하는 브랜치
- feature : 기능을 개발하는 브랜치
- Pre-commit
- CI/CD - black, isort, autoflake → flake8
- Git hub action
- Pre-commit : flake8
- Commit Convention
2. 프로젝트 팀 구성 및 역할
- EDA: 용찬
- Data: 건우, 단익
- Model: 재덕, 석희
3. 프로젝트 수행 절차 및 방법
1) EDA
a. 문제 정의
- Entity의 위치가 embedding size인 512를 넘어가는 데이터 확인
- Embedding size를 넘어가는 데이터 drop
- 한자가 포함되어 있는 데이터 확인
- hanja 라이브러리를 통한 한자-한국어 변환
- Baseline preprocessing 함수 오류 확인
- Entity type별 편향 확인¹⁾
- Entity type별 class restriction 실험b. 데이터 시각화
- Sentence 문장 길이 시각화
- Train, test data 분포가 동일한 것 확인
- Label 분포 시각화
- Source column 시각화
- Wikipedia, wikitree, policy_briefing 분포 확인
- 문어체 데이터로 pre-training한 모델에 집중
c. An Improved Baseline for Sentence-level Relation Extraction²⁾

위 다섯 가지 실험 모두 실행한 결과 성능 개선을 이루어내지는 못했습니다.
2) Model
a. Pytorch Lightning refactoring
- Pytorch Lightning 이식 및 실험 지원
b. Training Config
- Optimizer
- AdamW
- weight decay : Overfitting을 방지하기 위해 추가
- LR Scheduler
- constant_warmup : 정해진 step까지 LR이 선형적으로 증가하며 이후 고정된 값으로 학습
- cosine_warmup : warm up 과정 이후 cosine 함수를 통해 LR scaling 수행
- LR finder : Pytorch Lightining의 lr_finder 기능을 통해 초기 LR 설정³⁾

- Loss Function
- CrossEntropy : (baseline loss) input logits과 target 사이 cross entropy loss 계산
- Focal Loss : class imbalance dataset에서 class 별 가중치를 loss에 반영하기 위해 사용⁴⁾
- Label Smoothing Loss : hard target을 soft target으로 바꾸어 모델의 over confidence문제를 개선하기 위해 사용
- F1 Loss : classification loss 계산하기 위해 사용
- seed_everything & deterministic을 사용하여 재현 보장
- Mixed precision : GPU resource를 효율적으로 사용하며 연산속도 증가
- Stratified KFold : 불균형한 데이터셋이기에 모델 성능 일반화를 위해 사용
- Batch Size Finder : largest batch size를 찾는 기능
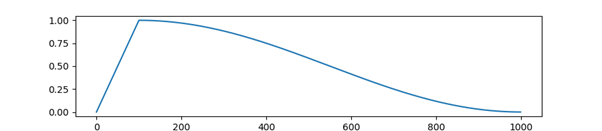
- 실험 결과, LR Scheduler 중 cosine warmup 을 사용했을 때 성능향상을 보였습니다. 이는 schduler가 초기에 워밍업 기간을 가짐으로써, 모델이 early over-fitting되는 것을 방지할 수 있었습니다.
- c. 논문 구현
- R-Roberta : R-bert 매커니즘을 Roberta에 적용⁵⁾
- CoRE: Counterfactual Analysis based Relation Extraction⁶⁾
3) Data Experiments
a. Data Augmentation
- Data pre-processing : EDA를 통해 한자, 영문자 등의 문자 비율이 많은 것을 확인했고, 한자를 (한자)라는 형태로 전처리하여 데이터 성능을 비교하였습니다. 한자 전처리한 모델(roberta-base_hanja_16_1e-05) : test_auprc 0.465 향상되었으나 test_accuracy,test_f1는 원본 데이터 모델이 더 높은 성능을 갖고 있어 위 실험은 제외했습니다.
- Back Translation : 한-영-한 역번역을 시도하려고 하였으나, EDA를 통해 대부분의 영문자를 포함한 단어는 고유명사로 확인되어 한-일-한 역번역을 진행했습니다. 역번역 데이터 20,011 rows를 추가하였지만, 원본 데이터의 성능이 더 높게 나와 위 실험을 제외했습니다.
- EDA(easy data augmentation)를 시도하려고 하였으나, 이전 기수에서 실패한 실험으로 확인되어 제외했습니다. 특히, SR(동의어 교체)를 시도하였으나 교체할 entity 단어는 지명, 이름, 고유명사 단어가 많아서 유의어 교체할 데이터가 상대적으로 적은 편으로 확인되어 제외했습니다.
- Generation Model : 생성 모델(koGPT3)을 사용하여, sub-obj entity를 활용한 새로운 문장을 구현하는 하는 테스트를 진행했습니다. 하지만 두 entity관계를 제대로 나타내는 문장을 제대로 구현하지 못해 위 실험은 제외했습니다.
- Masked Language Model : 문장에 sub,obj entity 부분을 [MASK]로 처리하고 bert 모델로 [MASK]의 새로운 단어를 찾는 실험을 진행했습니다. 기존 entity와 다른 단어를 생성하게 하여 새로운 entity를 추가하였습니다. 증강 데이터 58,446 rows를 추가한 실험 결과, 원본 데이터보다 향상된 성능을 확인하지 못하여 위 실험은 제외되었습니다.
b. 논문 구현
- Unipelt, Lora : finetuning 시 전체 parmeter 를 학습하는 것이 아닌 추가적으로 학습가능한 파라미터를 모델에 추가하여 학습의 효율성을 향상시키는 실험을 진행하고자 했습니다. 하지만, 모델 수정에 어려움이 있어 구현을 완료하지 못했습니다.
4. Optimization
a. ELECTRA, RoBERTa, R-RoBERTa, BigBird 등 다양한 PLM에 대한 최적화 수행
- batch size:16
- loss*: CrossEntropy loss, Label smoothing
- learning rate scheduler*: cosine warmup scheduler, constant warmup scheduler
- Initial learning rate*: LR finder 기반 모델별 최적 learning rate 사용 (ex. roberta-large: 2.12e-05)
5) Ensemble
a. Soft Voting
- 모델별 micro-f1 score를 기준으로 가중 평균을 구하는 방식으로 구현했습니다.
- ELECTRA(3개), RoBERTa(4개), R-RoBERTa(2개)를 앙상블한 결과, micro-f1 74.1204, auprc 77.1611 성능이 가장 좋았습니다.
b. Hard Voting
- 예측된 라벨값인 pred_label을 기준으로 최빈값을 도출하는 방식으로 구현했습니다.
- Soft Voting된 probs를 유지하고, 앙상블된 ELECTRA, RoBERTa, R-RoBERTa, BigBird를 앙상블한 결과, micro-f1 74.4339, auprc 77.1611로 성능이 가장 좋았습니다.
4. 프로젝트 수행 결과

- 최종 결과 14 위 (14/14), F1 기준 71.97 획득
5. 결론
PL사용, 논문 참고 등을 통해 다방면으로 코드 개선을 수행했으며, 데이터 분석 및 실험, 앙상블 과정을 통해 최종 결과를 도출
- 데이터 분석을 통한 데이터 품질 개선(data cleaning, data augmentation)
- 데이터셋에 적한한 PLM 선정 및 최적화
- 베이스라인 코드 개선
- PL 이식 및 다양한 기능 추가
- 논문 구현을 통한 추가적인 모델 개선을 수행
- R-roberta, CoRE, Unipelt 등의 논문을 참고 및 구현을 위한 실험 수행
- 다양한 결과에 대한 앙상블(Hard Voting)을 수행
6. Future Study
추가적인 개선 방향
- 데이터 불균형에 따른 개선 방법 필요
- focal loss 등을 사용하였으나, 개선되지 않음
- under/over sampling에 대한 추가 실험 필요
- Prompt를 활용하여 데이터 input을 변경하는 실험 필요⁷⁾
- Baseline: sub_entity [SEP] obj_entity [SEP] sentence
Prompt: [CLS] sub_entity와 obj_entity의 관계는? [SEP] sentence
- Baseline: sub_entity [SEP] obj_entity [SEP] sentence
7. Appendix
- Relation Classification with Entity Type Restriction
- An Improved Baseline for Sentence-level Relation Extraction
- Cyclical Learning Rates for Training Neural Networks
- Focal Loss for Dense Object Detection - “Focal Loss **focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training.”
- Enriching Pre-trained Language Model with Entity Information for Relation Classification - R-RoBERTa 구현 참고
- Should We Rely on Entity Mentions for Relation Extraction? Debiasing Relation Extraction with Counterfactual Analysis - “CoRE (Counterfactual Analysis based Relation Extraction) debiasing method that guides the RE models to focus on the main effects of textual context without losing the entity information”
- PTR: Prompt Tuning with Rules for Text Classification
'Projects' 카테고리의 다른 글
| [Open-domain question answering(ODQA)] 3. Retrieval Experiment - ElasticSearch(엘라스틱 서치) (0) | 2023.01.08 |
|---|---|
| [Open-domain question answering(ODQA)] 2. EDA, Pytorch Lightning Refactoring (0) | 2023.01.08 |
| [Open-domain question answering(ODQA)] 1. 프로젝트 개요 (2) | 2023.01.08 |
| NLP 자동차 주제 데이터 제작 프로젝트 (0) | 2022.12.28 |
| Semantic Text Similarity(문장 간 유사도 측정) 프로젝트 (0) | 2022.11.07 |



