https://arxiv.org/abs/2103.10385
GPT Understands, Too
Abstract
- 전통적인 GPT finetuning으로는 NLU task에서 낮은 성능을 보임
- P-tuning을 이용하여 GPT를 튜닝하면, NLU task에서 비슷한 사이즈의 BERT에 비견되는 성능을 보임
- 지식 탐색 벤치마크 LAMA에서 20% 성능 향상
- SuperGlue 벤치마크에서 비슷한 사이즈의 BERT에 비견되거나 outperform한 결과를 냄
- P-tuning은 BERT의 fewshot setting, supervised setting에서도 성능을 향상시킴
- few-shot SuperGlue benchmark에서 Sota 성능을 냄

- large scale로 갈 수록 BERT보다 GPT 성능 좋지 못함.
- 그러나, P-tuning을 적용할 경우 GPT 성능 더 좋음
Motivation
- Manual Prompt를 사용하여 Prompt engineering을 하면 단어 하나만으로도 성능 차이가 많이 나는 경우들이 있음
- 토큰 하나의 차이로 성능차이가 많이나게 되는 것은 안정적이지 못함
- Best manual prompt를 찾을 확률이 너무 낮음
-> gradient descent를 통해 token embedding을 학습을 통해 찾자

- 'In' 하나 단어만 들어갔을 뿐인데 큰 차이 보임
Method - Architecture

- (b) P-tuning
- h_0~h_i : P 임베딩
- e : 임베딩 룩업, continuous한 임베딩
- h_i+1~h_m : 프롬프트 처럼 사용
- Prompt Encoder : index를 집어 넣어 prompt 생성. LSTM 통과 hidden state 만듦
- 학습을 통해 Prompt Encoder 개선, P 임베딩 개선
- B-LSTM을 통한 Prompt Encoder 사용 이유. 학습 수렴 속도가 더 빠름

Result

- LLAMA P-tuning 성능 좋음
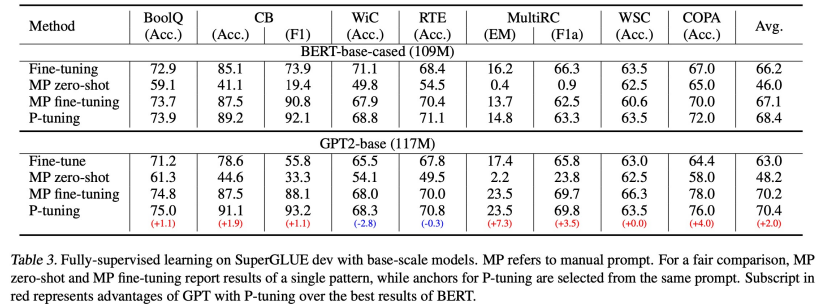
- base 사이즈 모델 성능 비슷

- large 모델 P-tuning의 GPT 성능 개선 큼
- BERT에 비견되거나 더 높음

- fewshot 성능 비교
- NLI task



