https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
Abstract
- LLM이 계속 커지면서 Full fine-tuning으로 모델을 학습하는 것이 less feasible 해지고 있다
- GPT-3 같은 모델을 Full fine-tuning 하는 것은 엄두도 못낼 정도로 비쌈
- LoRA는 LLM의 weight는 고정하고 추가적인 trainable 파라미터를 각 트랜스포머 레이어에 inject함
- LoRA는 학습 파라미터를 10,000배 줄여줌
- Full finetuning에 비견되거나 더 나은 성능
- Adapter류의 PEFT 기법과 inference 속도가 느려지지 않음 (LoRA는 병렬로 연산)
Motivation
- Overparameterized model은 사실 Low instrinsic dimension에 거주한다는 것에 영감을 받음
-> 고유차원은 낮은 차원에 있음
- 마찬가지로 Weight의 변화도 Low instrinsic rank가 있을 거라고 가정함

- 일반적으로는 파란색 영역에서만 linear를 태움 -> dxd -> d 차원.
- LoRA는 빨간색 영역 추가하여 학습 -> dxr -> rxd -> d 차원
- 여기서 Low intrinsic rank가 r(작은 차원)
- 차원을 줄이면 사용되는 파라미터 사이즈가 줄어듬
- W_0x : 파란색 ΔW_x : 빨간색
- 기존의 weight W와 같은 shape
- 학습이 완료되면 기존의 W에 merge 할수도 있음
- LoRA 적용 위치
- Q, K, V projection
Full fine-tuning objective
- 질문 x가 주어지고, 생성하고 있는 y<t, 예측 y_t
- 파라미터 P_Φ 학습
LoRA objective
- 파라미터 P_Φ 둘로 쪼개짐
- 변화된 ΔΦ 찾아냄
Result

- Fine-Tune LoRA 속도
- Adapter류 보다 더 빠름
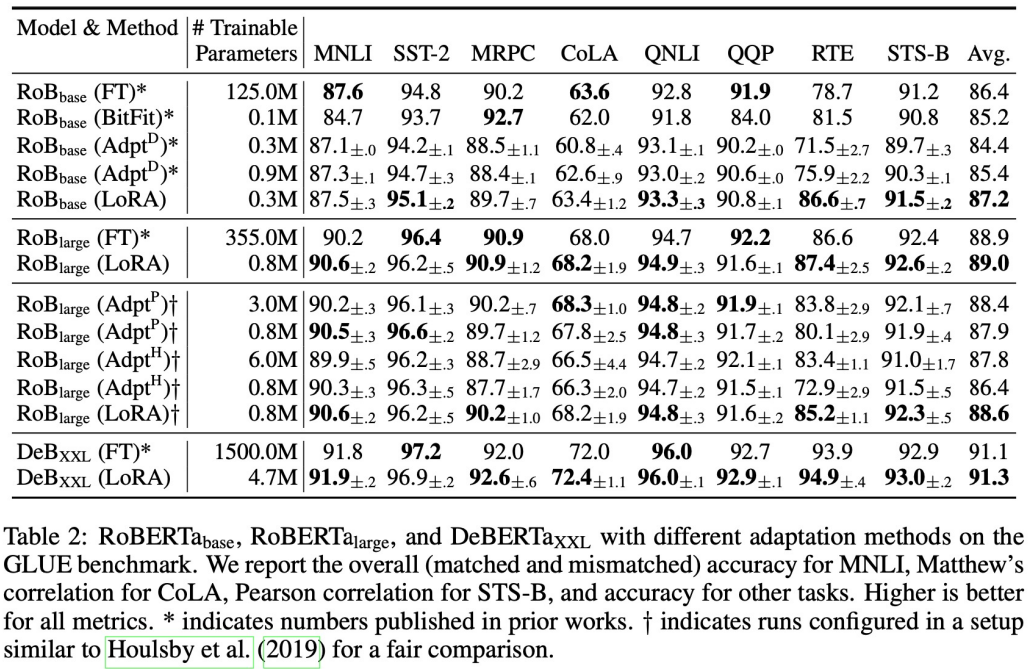
- Encoder류 성능 비교
- FT과 비견되게 좋음, Adapter 보다 좋음
- FT 파라미터 125M, LoRA 파라미터 0.3M
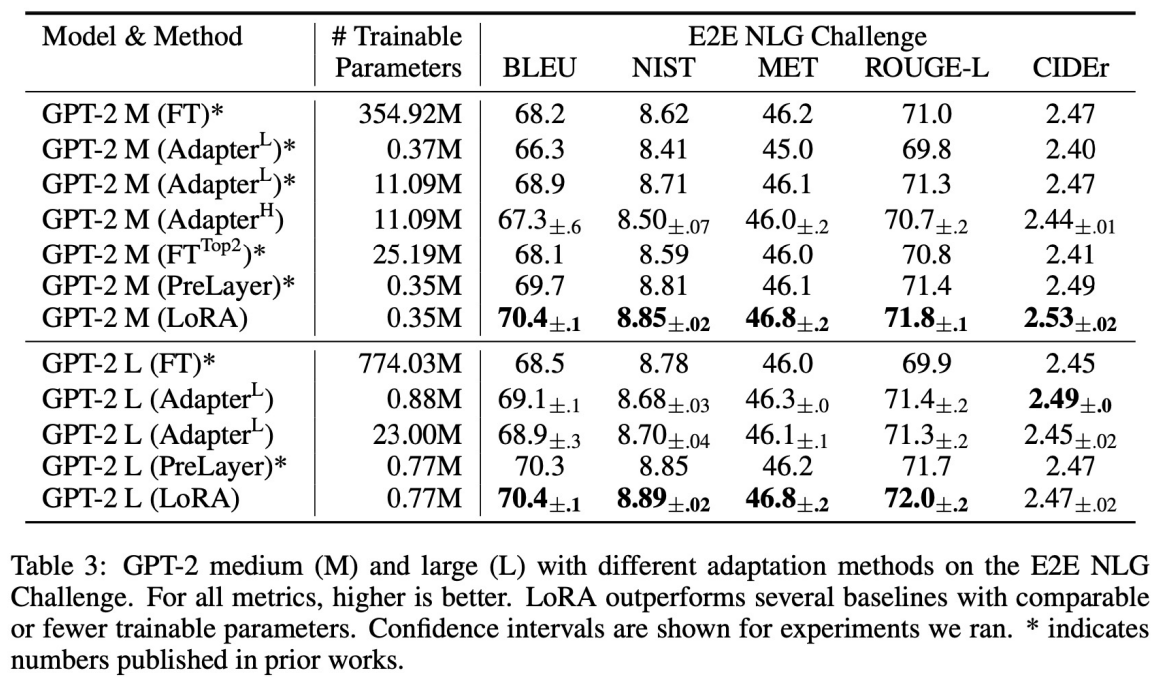
- Decoder류 성능 비교
- 성능 좋음
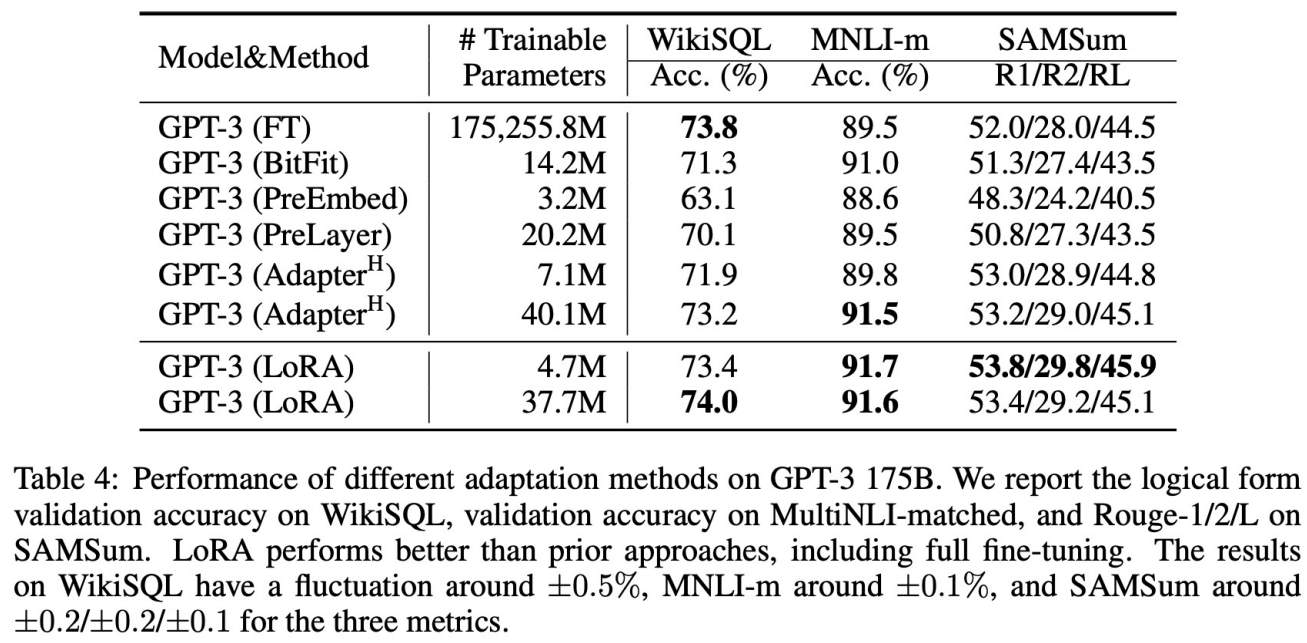
- 서로 다른 methods 비교
- 역시 성능 좋음
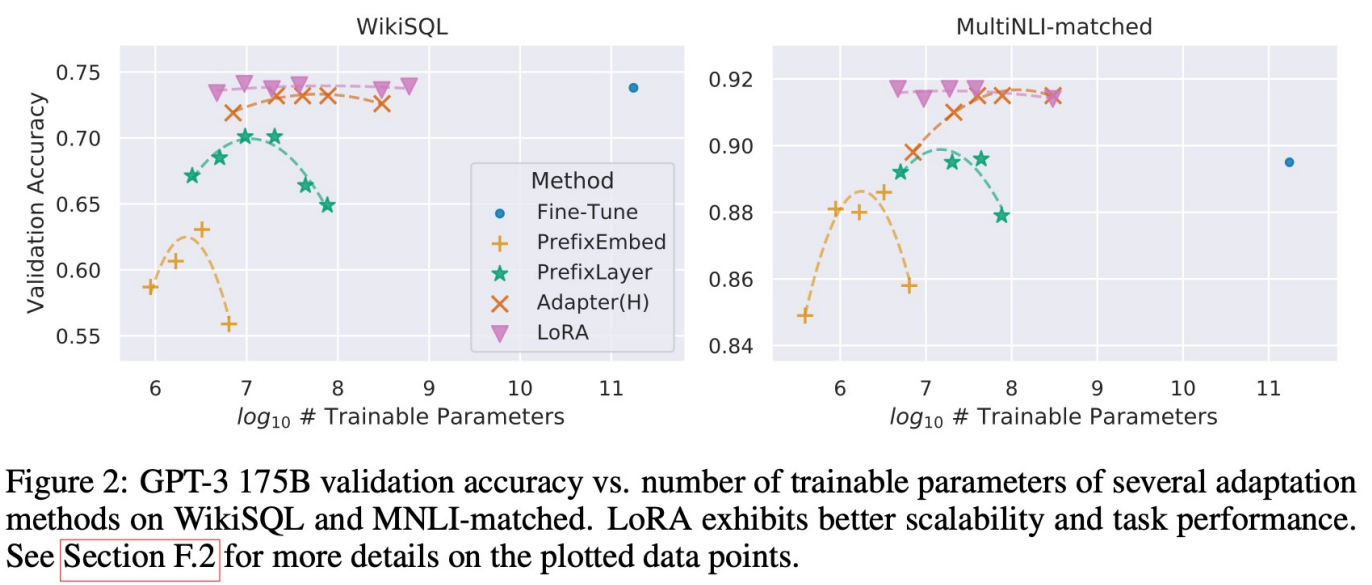
- LoRA는 파라미터 변경하더라도 유사하게 준수한 성능을 보임
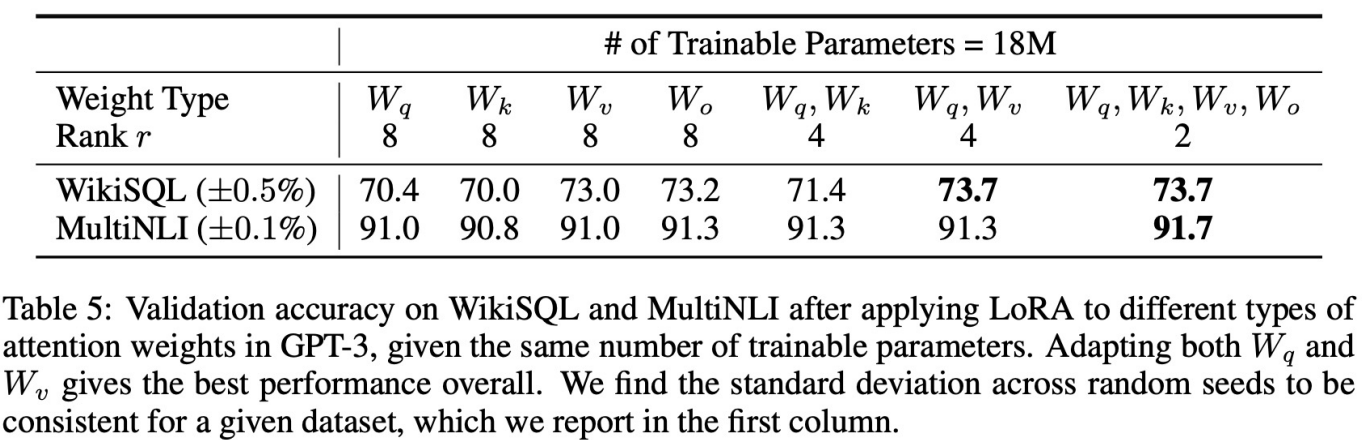
- 어떤 weight에 LoRA를 적용해야 할 까?
- rank 2일 때 좋은 성능
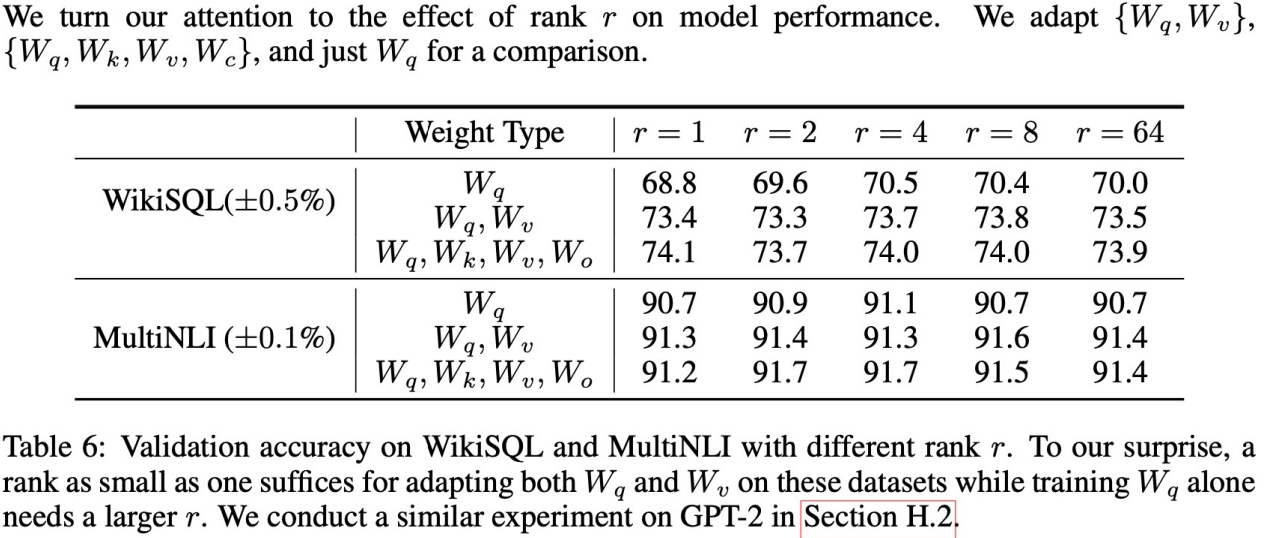
- rank는 몇으로 해야 할 까?
- 1, 2, 4, 8 적은 차원에서도 좋은 성능
Conclusion
- LoRA(Low Rank Adaptation): 현존하는 대규모 언어 모델을 FFT(Full-fine tuning)하는 것은 필요한 하드웨어와 저장/스위칭 비용 때문에 비싸다. 이에 대한 효율적인 해결책으로 LoRA를 제안한다. LoRA는 추론 지연을 발생시키지 않고, 입력 시퀀스의 길이를 줄이지 않으면서도 높은 모델 품질을 유지한다.
- 더욱이, 대부분의 모델 파라미터를 공유함으로써 서비스로 배포될 때 빠른 작업 전환을 가능하게 한다. -> Backbone 모델은 두고, Task A LoRA weight, Task B LoRA weight를 바꿔가며 사용 가능
- 모델 향상과 원리에 대한 이해: LoRA는 다른 효율적인 적응 방법과 결합될 수 있으며, 이는 각기 다른 개선 방향을 제공할 수 있다. 미세 조정이나 LoRA의 기작은 아직 명확하지 않다. 특히, 사전 훈련 과정에서 학습된 특징들이 어떻게 downstream task에 잘 적용되는지에 대한 이해는 부족하다. LoRA는 이를 이해하는 데 있어 FFT보다 더 다루기 쉽게 만들어 줄 것으로 믿는다.
- 더욱 원칙적인 접근 방식이 필요 : LoRA를 적용할 가중치 행렬을 선책하기 위해 주로 휴리스틱을 사용하고 있다. 이에 대한 더 원칙적인 방법이 있는지에 대한 질문이 제기된다. 또한, ΔW의 rank-deficiency은 W도 rank0deficient일 수 있다는 가정을 제시하고 있으며, 이는 미래의 연구에 영감을 제공할 수 있다.



