논문 링크 - https://openreview.net/pdf?id=zeFrfgyZln
ABSTRACT
- 학습된 dense representation 은 다양한 장점을 가지고 있지만 sparse retrieval에 비해 성능이 좋지 않았음.
- 본 논문에서는 DR(Dense retrieval)의 bottleneck이 mini-batch training에서 uninformative negatives sample 때문이라는 점을 이론적으로 보여줌.
- diminishing gradient norms → large gradient variances → slow convergence
- 이에 해당 논문에서는 entire corpus에서 globally하게 hard training negatives를 선택하는 ANCE(Approximate nearest neighbor Negative Contrastive Learning)를 제안.
1. Introduction
- 많은 language system 들은 ODQA를 위해 두 단계로 구성되어 있음.
- (1) 관련 문서 도출 (2) 해당 문서 내 정답 탐색
- later stage는 딥 러닝 기술을 통해 발전한 반면, first stage(retrieval)는 여전히 BM25와 같은 sparse retrieval(matching discrete bag-of-words)에 의존하고 있음.
- Dense Retrieval(DR)은 neural network을 통해 학습되어 semantic 정보를 포함하고 있기에 기존 Sparse Retrieval 의 한계점인 vocabulary mismatch를 근본적으로 극복할 수 있는 가능성이 있음.
- 그러나 DR은 representation space를 학습할 때 수백만 또는 수십억 개의 문서가 있는 corpus에서 관련 없는 모든 것을 구별해야 한다는 한계가 있고, 이를 해결하기 위해 적절한 negative instances를 구성할 필요가 있음.
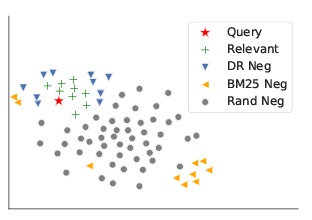
- 위 그림에서 볼 수 있듯이 sparse model을 활용하여 얻은 negative sample은 query와 유사한 negative sample과는 상당히 다르다는 한계가 있음. 이러한 한계를 해결하기 위해 DR을 위한 negative training instances를 construct하는 다양한 방법이 탐구되어 옴.
- In-batch local negatives는 word를 배우는 것 혹은 visual representations에는 효과적이지만 spare-retrieved negatives에 비해 유의미하게 좋지 않음.
- 본 논문에서는 먼저 negative sampling으로 dense retrieval training의 수렴을 이론적으로 분석하였고 local in-batch negatives이 기존 DR의 bottleneck임을 보임.
- 해당 분석을 바탕으로 본 논문에서는 Approximate Nearest Neighbor Negative Contrastive Estimation (ANCE)를 제안.
- random 혹은 in-batch local negatives 대신 entire corpus에서 retrieve하기 위해 optimized된 DR 모델을 사용하여 global negatives를 구성.
- ANCE 방법은 인스턴스별 gradient norm의 상한을 높이고 stochastic gradient estimation의 분산을 줄여서 더 빠른 학습 수렴을 얻을 수 있음.
- 비동기적으로 업데이트된 ANN index를 통해 ANCE를 수행함.
- 모델 학습과 inference를 병렬적으로 수행하기 위해 Encoder의 마지막 체크포인트를 이용하여 inference를 수행하며, inference 결과를 바탕으로 ANN index를 refresh하는 방식을 사용함.
- ANCE 방식의 negatives가 local negatives보다 gradient norm이 크다는 것을 경험적으로 입증하였고 이에 해당 방식이 DR 모델의 수렴에 도움이 된다고 주장함.
2. PRELIMINARIES
Task Definition
- DR은 학습된 embedding space에서 similarities를 사용하여 retrieval score인 을 계산함.
- = sim()
- 는 쿼리 또는 문서를 인코딩하는 representation 모델
- sim()는 유사도를 구하기 위해 사용되는 코사인 혹은 내적 함수
BERT-Siamese Model
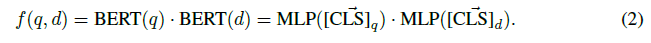
- BERT를 통해 query와 document를 각각 인코딩 함으로써 앞선 수식의 의 역할을 수행함.
- [CLS] token의 representation 통해 이를 계산함.
Learning with Negative Sampling
- query 가 주어졌을 때 relevant document 와 irrelevant ones 을 통해 얻어지는 최적의 값은 다음과 같음.
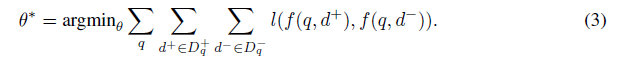
- loss 은 BCE(Binary Cross Entropy), hinge loss or NLL(negative log likeihood) 등을 사용함.
- DR의 unique한 문제는 entire corpus에 대해 irrelevant documents를 분리해야 한다는 점( = \ ).
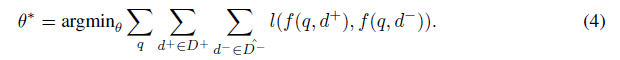
- DR모델에 BM25을 통해 얻은 negatives 를 샘플링함으로써 좋은 결과를 얻을 수 있지만 이는 단지 sparse retrieval을 모방하는 방법.
- contrastive learning에서와 같이 local mini-batches에서 negatives를 샘플링하는 것은 sparse retrieval에 비해 성능이 좋지 않은 한계를 지님.
3. ANALYSES ON THE CONVERGENCE OF DENSE RETRIEVAL TRAINING
이 섹션에서는 dense retrieval training의 수렴을 이론적으로 분석함.
3.1 ORACLE NEGATIVE SAMPLING ACCORDING TO PER-INSTANCE GRADIENT-NORM
인스턴스별 gradient-norm을 고려하면 oracle negative sample 을 얻을 수 있음
- = , be the loss function on the training triple
- : 에 대한 negative 샘플링 분포
- : negative 인스턴스의 샘플링 확률
- importance sampling을 통한 stochastic gradient decent(SGD) 단계

- : t step 파라미터
- : t+1 step 파라미터
- : 네거티브 전체 개수
- : scaling factor
→ 이러한 SGD의 converge rate로 optimal 구함
variance diminishing의 유도에 따른 weighted gradient, convergence rate 수식

- 이는 SGE 의 분산을 최소화하는 분포 에서 샘플링하여 더 나은 convergence rate을 얻을 수 있음을 보여줌.
- 분산은 negative 샘플링의 stochastic gradient가 모든 negative에 대한 전체 그래디언트를 얼마나 잘 나타내는지를 반영함.
- 직관적으로 stochastic estimator가 안정적이고 분산이 작은 것을 선호함
- importance sampling에서 다음과 같은 최적 의 분포가 존재
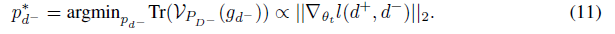
- 이에 기울기 분산에 Jensen의 부등식을 적용하면 Eqn. 11은 최소값을 달성
- Eqn. 11은 convergence rate가 per-instance gradient norms에 비례하는 negatives를 샘플링하여 개선될 수 있음
- negative instance with larger gradient norm는 non-stochastic training loss을 줄일 가능성이 더 높으므로 (더 효과적인 negative sample이 되므로) 그래디언트가 감소하는 인스턴스보다 더 많이 샘플링해야 함
3.2 UNINFORMATIVE IN-BATCH NEGATIVES AND THEIR DIMINISHING GRADIENTS
Diminishing Gradients of Uninformative Negatives
- gradient norms는 다음과 같은 상한을 도출함

- : 레이어의 수
- : 중간 레이어 pre-activation와 gradients로 구성

- 해당 수식은 last layer의 gradient
- → 0
- loss function에 대해 loss가 0이 되면

- 마지막 레이어의 gradient norm 또한 0이 됨
→ uninformative negative samples with near zero loss을 사용하면 아래와 같은 체인이 생기게 됨
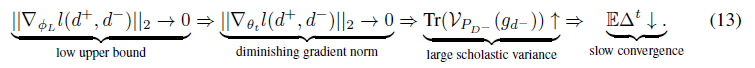
→ uninformative negative samples은 감소하는 gradient norm, SGE의 더 큰 분산 및 less optimal learning convergence을 발생
Inefficacy of Local In-Batch Negatives
- in-batch local negatives가 informative한 샘플을 제공하지 못하는 이유를 다음과 2가지 로 제시
- 1) 가 있고 배치 크기는 corpus 크기보다 훨씬 작습니다.
- 2) , 소수의 negatives만이 informative하고 corpus의 대부분은 관련이 없습니다.
- , : 구별하기 어려운 informative negatives의 집합
- : 배치 크기
- 두 조건 모두 대부분의 DR에서 나타남
- 이 두 가지를 함께 사용하면 임의의 미니 배치가 meaningful negatives = 을 포함할 확률이 0에 가까워짐
- local training batches에서 negatives를 선택하면 optimal training signals를 제공할 가능성이 낮음
4. APPROXIMATE NEAREST NEIGHBOR NOISE CONTRASTIVE ESTIMATION
ANCE 무엇인지, 비동기식으로 업데이트하는 것 Asynchronous Index Refresh이 무엇인지 구체적 설명
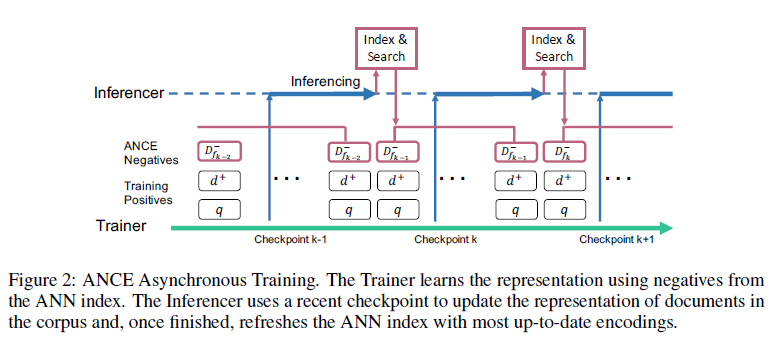
ANCE
- ANCE는 ANN index로 부터 얻은 documents에서 negatives를 샘플링
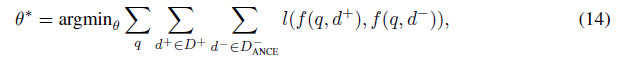
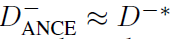
- 는 와 유사함
→ informative negatives: training loss ↑, gradient norm의 상한 ↑, → slow convergence 방지
Asynchronous Index Refresh
- stochastic training 중, DR 모델 는 각 미니배치마다 업데이트
- 새로운 ANCE negatives를 고르기 위해 두 가지 operations 필요
- 1) Inference: 업데이트된 DR 모델로 corpus의 모든 문서 표현을 refresh합니다.
- 2) Index: 업데이트된 representations을 사용하여 ANN index을 재구성합니다.
- IInference는 training batch보다 훨씬 더 큰 전체 corpus에 대한 forward pass가 필요하기 때문에 배치마다 compute하기 어려움
- 따라서 비동기 인덱스로 구현하고, m 배치마다 체크포인트 로 ANN 인덱스를 업데이트
- 동시에 Trainer는 로부터 를 사용하여 stochastic learning을 계속 수행
- corpus가 다시 인코딩되면 Inferencer는 인덱스()를 업데이트하고 trainer에게 제공
- 이 프로세스에서 ANCE negatives()는 비동기식으로 업데이트되어 async-gap으로 stochastic training을 따라 잡음
5. EXPERIMENTAL METHODOLOGIES
이 섹션에서는 실험 설정에 대해 설명합니다.
Benchmarks
- web search
- TREC 2019 Deep Learning (DL) Track
- MS MARCO corpus의 retrieval passages 또는 documents에 대한 Bing의 웹 쿼리가 주어진 표준 임시 검색 벤치마크
- OpenQA
- Natural Questions (NQ), TriviaQA (TQA)
- metric: Coverage@20/100(Top-20/100 passages에 답이 포함되어 있는지 여부를 평가)
- readers: NQ의 RAG-Token 및 TQA의 DPR 리더
Baselines
- TREC DL
- 동일한 BERT-Siamese를 사용하여 다양한 DR baseline을 수행하였지만 training negative 구성은 다르게 하였습니다.
- 배치의 무작위 샘플링(Rand Neg), BM25 상위 100개에서 무작위 샘플링(BM25 Neg), BM25와 random negatives의 1:1 조합(BM25 + Rand Neg)
- NCE Neg를 사용한 contrastive learning/Noise Contrastive Estimation 비교
- 동일한 BERT-Siamese를 사용하여 다양한 DR baseline을 수행하였지만 training negative 구성은 다르게 하였습니다.
- OpenQA
- DPR, BM25, DPR+BM25 비교
Implementation Details
- TREC DL
- MARCO official BM25 Negatives를 사용하여 처음 훈련되는 "BM25 Warm UP" 설정 포함
- TREC DL의 모든 DR 모델은 RoBERTa 베이스에서 fine-tuned
- OpenQA
- DPR 체크포인트 사용
- long documents를 BERT-Siamese에 fit하기 위해 FirstP와 MaxP를 사용
- FirstP : uses the first 512 tokens of the document
- MaxP : where the document is split to 512-token passages (maximum 4) and the passage level scores are max-pooled.
- ANN 검색은 Faiss IndexFlatIP 인덱스를 사용
- 4개의 V100 32GB GPU에서 배치 크기 8과 gradient accumulation step 2를 사용하였습니다.
- 32GB V100 GPU 1개, Intel(R) Xeon(R) Platinum 8168 CPU 및 650GB RAM 메모리를 사용하여 ANCE 효율성을 측정

6. EVALUATION RESULTS
- ANCE의 효과와 효율성을 평가
- ANCE training의 convergence와 asynchronous gap의 영향
6.1 EFFECTIVENESS
- Table 1
- 웹 검색(표 1)에서 ANCE는 BERT 기반 DeepCT를 포함하여 모든 sparse retrieval을 훨씬 능가
- 학습 전략이 다른 DR 모델 중에서 ANCE는 문서 검색에서 sparse retrieval을 robustly하게 능가하는 유일한 모델입니다.
- OpenQA의 retrieval accuracy에서 ANCE DPR 및 BM25(DPR+BM25)조합을 능가
- 또한 ANCE retriever을 사용하여 같은 readers 기준 end-to-end QA 정확도를 향상시킵니다.
- ANCE의 효과는 real production에서 훨씬 더 많이 관찰
- 모든 DR 모델 중에서 ANCE는 retrieval 정확도와 reranking accuracy 정확도의 간격이 가장 작음
- 이는 training retrieval models에서 global negatives의 중요성을 보여줍니다.
- ANCE retrieval은 BERT-Siamese가 term 수준 상호 작용 기반 BERT Reranker를 사용하는 cascade IR의 정확도와 거의 일치
- ANCE를 사용하면 검색 관련성을 효과적으로 포착하는 representation space를 얻을 수 있음
6.2 EFFICIENCY
- Table 5 TREC DL 문서에서 ANCE(FirstP)의 효율성
- 쿼리당 100개의 문서를 retrieve/rank 지정하기 위한 online latency에서 DR은 BERT Rerank보다 100배 더 빠릅니다. 이는 문서 인코딩이 쿼리와 별도로 오프라인에서 계산되는 BERT-Siamese의 이점입니다.
- 상호 작용 기반 BERT Reranker는 쿼리 및 후보 문서 쌍당 한 번씩 BERT를 실행합니다.
- training computing의 대부분은 ANCE 네거티브 구성에 대한 corpus의 인코딩을 계산하는 데 있으며, 이는 index refresh asynchronous으로 완화됩니다.
6.3 EMPIRICAL ANALYSES ON TRAINING CONVERGENCE
- Fig. 3 dense retrieval에서 검색 관련성의 long tail 분포
- Fig. 3에 표시된 것처럼 retrieval socres가 상당히 높은 query가 query 당 몇 개의 인스턴스가 있는 반면 대부분은 long tail을 형성
- retrieval/ranking에서 핵심 과제는 가장 높은 점수를 받은 항목 중에서 relevant 항목을 구별하는 것입니다.
- 가장 높은 점수를 받은 negatives와 중첩하여 informative한 negatives(*)를 포함한 local in-batch 네거티브의 확률을 측정
- NCE Neg 또는 Rand Neg를 사용하는 이 확률은 이론이 보여주는 것과 같이 0입니다.
- BM25 Neg와 dense retrieval 사이의 overlap은 15%인 반면 ANCE negatives의 overlap은 63%에서 시작하여 설계상 100%로 수렴
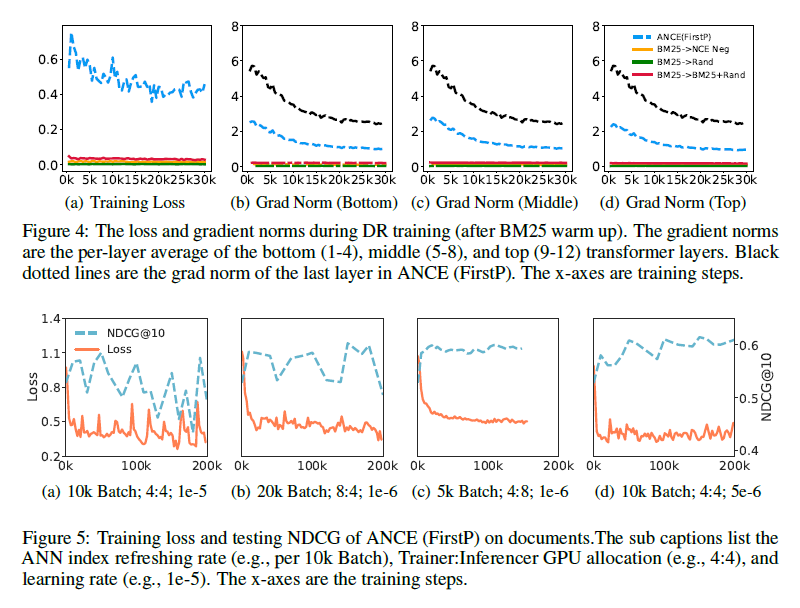
Fig. 4 DR training 중 training loss 및 pre-clip gradient norms
- local negatives가 더 낮은 loss, diminishing gradient norm, non-ideal importance sampling로 이어지고 이에 slow convergence로 이어진다는 것 검증
- uninformative local negatives의 gradient norms이 거의 0에 가까운 반면 ANCE global negatives는 더 높은 gradient norms을 유지합니다.
- ANCE 훈련 중 BERT-Siamese 모델의 마지막 레이어의 gradient norms(그림 4의 검은색 점선)은 다른 레이어보다 일관되게 크며 경계의 상한과 일치합니다.
- 로컬 네거티브의 gradient norms은 0에 가까운 경계, ANCE 글로벌 네거티브의 gradient norms은 수십 배 더 큼
→ ANCE가 oracle importance sampling distribution를 더 잘 근사, 학습 수렴을 개선한다는 것 확인
6.4 IMPACT OF ASYNCHRONOUS GAP
- Fig. 5
- 효율성 제약 조건은 ANCE training에서 asynchronous gap(async-gap)을 enforce합니다. negatives는 optimized된 DR 모델의 이전 단계에서 인코딩을 사용하여 선택됩니다.
- async-gap은 Trainer vs Inferencer의 컴퓨팅 리소스 할당과 learning rate에 의해 결정되는 target index refreshing rate에 의해 결정됩니다.
- large learning rate 또는 낮은 refreshing rate에서 큰 async-gap은 refreshed index가 크게 변경하기에 training을 불안정하게 함
- index refreshing과 training에 동일한 양의 GPU를 할당함으로써 async-gap의 영향을 줄일 수 있음
7. RELATED WORK
- ANN을 통해 임베딩 공간에서만 retrive를 수행한 단순한 DR이 SOTA를 달성한 것은 해당 모델이 sparse retrieval과 큰 차이점을 가짐을 시사
- contrastive representation에 대한 최근 연구는 또한 큰 candidate pool에서 negatives를 샘플링하는 이점을 보여줌
- 컴퓨터 비전에서 recent batches의 negative candidate pool을 유지하며 momentum과 함께 representation을 updating 함으로써 negative sampling pool 크기와 training batch size의 의존관계를 제거. 이 확대된 negative pool은 unsupervised visual representation learning을 크게 개선
- parallel work은 memory bank에서 negatives를 샘플링하여 DPR을 개선. 여기서 negative candidates의 representations은 frozen되어 더 많은 negative candidates를 저장할 수 있음.
- ANCE는 더 큰 local pool 대신 비동기적으로 업데이트된 ANN index를 사용하여 전체 corpus에서 globally하게 negatives를 구성.
- dense retrieval은 많은 언어 시스템의 핵심 구성 요소입니다. 더 나은 retrieval accuracy는 다른 많은 언어 시스템에 도움이 될 수 있음
8. CONCLUSION
- 해당 논문은 DR에서 representation learning의 convergence에 대한 이론적 분석을 수행
- 일반적으로 local negatives를 사용하여 학습된 DR은 bottlenect이 존재
- 그렇기에 ANCE는 전체 corpus에서 전역적으로 training negatives를 구성하여 bottleneck을 제거하도록 제안
- 실험을 통해 web search, OpenQA, commercial search engine에서 ANCE의 이점을 보여줌
- ANCE negatives는 훨씬 더 큰 gradient norms을 갖고, stochastic gradient variance을 줄이고, 수렴을 개선한다는 이론을 경험적으로 검증
Discussions
R1
- The analysis on why in-batch local negatives are ineffective (in section 3) does not seem to be very insightful. Also, I did not see a big connection between this analysis and the negative sampling technique proposed in the following section.
- The idea of maintaining a set of global negatives is not new, and refreshing index asynchronously has also been explored in [Guu et al. 2020]
We do not claim the novelty in refreshing the ANN index asynchronously. It is a technique that used both by us and REALM, but for different purposes.
- ANCE focuses on representation learning for dense retrieval and uses the ANN index to construct global hard negatives for contrastive learning. REALM focuses on grounded language modeling and uses the ANN index to find grounding documents.
- The retrieval part in REALM is indirectly trained by the language model loss, while ANCE focus on the retrieval itself. The comparison in the End-to-end QA accuracy shows that ANCE provides better retrieval accuracy which leads to better answer accuracy than REALM.
On the contribution of this work:
- It is intuitive that improving the difficulty of negatives is useful. Nevertheless, we are among the first to theoretically show the needs of harder negatives and the intrinsic limitation of the widely used local negatives in contrastive learning.
- To the best of our knowledge we are among the first to provide both theorical analyses and an effective solution to construct global negatives in contrastive representation learning.
R2
- The only one thing that I believe might impair the utilisation of this method is that you need to reconstruct the embeddings every m batches. It takes 10h every reconstruction and it is not clear what happens every m batches.
- The main bottleneck of using top retrieved documents as negative instances is the computational burden of updating the ANN indexing per batch. Therefore, the authors propose to perform this updating less frequently. It would be nice to have more comprehensive experiment to show that how sensitive is the performance vs the frequency of index updates.
- The reconstruction of the embedding in the ANCE negative index is also paralleled on multiple GPUs. The forward pass is easy to parallel and in our experiments, we often use four or eight GPUs, equal to those used in the training side in this reconstruction. This reduces the reconstruction time to 2.5 or 1.25 hours. (We measure the time on one GPU in Table 5 for fair comparisons.)
정리
- DPR의 inbatch negative는 항상 효율적이지 않다
- BM25로 뽑은 negative sample을 hard negative로 많이 사용하고 있는데, 실제로 벡터를 시각화해보니 query와 거리가 멀었다 -> hard negative로서 random negative보다 멀었기에 한계점을 가진다
- 학습에 정말 도움이 되는 Negative sample을 뽑아야 한다
- 더 정보량이 많은, query와 유사하지만 negative인 sample을 잘 뽑는게 중요하다
- + dense retreicval - index 시간 너무 오래걸림 faiss 사용하는 것 중요
Uploaded by N2T



