
1. MRC(기계독해, Machine reading comprehension)란?
주어진 지문 (Context)를 이해하고 주어진 질의 (Query/Question)의 답변을 추론하는 문제
1.1. MRC 종류
1) Extractive Answer Datasets
- 질의(question)에 대한 답이 항상 주어진 지문(context)의 segment (or span) 으로 존재
- Cloze Tests
- Span Extraction
2) Descriptive/Narrative Answer Datasets
답이 지문 내에서 추출한 span이 아닌, 질의를 보고 생성된 sentence 형태
- MS MARCO
3) Multiple-choice Datasets
질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태
- MCTest
1.2. MRC Datasets
1.3. Challenges in MRC
1) Paraphrasing
단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해해야 하는 경우
위 그림에서 P1의 경우, 'selected'라는 단어가 있으므로 답을 유추하기 쉽다. 반면 P2의 경우, 단어 구성이 유사하지 않아 답을 유추하기 어렵다.
2) Coreference Resolution
대명사가 무엇을 지칭하는지 찾아내야 하는 경우
3) Unanswerable questions
지문 내에 답변이 존재하지 않는 경우
4) Multi-hop reasoning
여러 개의 document에서 질의에 대한 supporting fact를 찾아야 답을 찾을 수 있음
위 그림에서 Big Oak Tree State Park 찾기 위해, 여러 개의 document에서 Gulf Coastal Plain -> Southern United States -> United States of America 를 찾아야 함
1. 4. MRC의 평가 방법
1) Exact Match / F1 Score
- 대상: extractive answer, multiple-choice answer datasets
Exact Match (EM) or Accuracy
- 예측 값과 정답이 캐릭터 단위로 완전히 똑같을 경우에만 1점 부여, 하나라도 다른 경우 0점
- 맞은 sample 수 / 전체 sample 수
- 답변이 조금만 달라도 점수를 못 받는 문제가 발생 → F1 Score 사용
F1 Score
- 예측한 답과 ground-truth 사이의 token overlap을 F1으로 계산
- Precision: 불필요하게 예측값이 길어지면 하락
- Recall: 두 token들 중 겹치는 token이 적으면 하락
- 0점과 1점 사이의 부분 점수를 받을 수 있음
2) ROUGE-L / BLEU
- 대상: descriptive answer datasets
- Groud-truth과 예측한 답 사이의 overlap을 계산 + a
ROUGE-L Score
- 예측한 값과 ground-truth 사이의 overlap recall
- ROUGE-L ⇒ LCS (Longest Common Subsequence) 기반. 예측과 정답과 겹치는 subsequence 길이가 얼마인가
BLEU (Bilingual Evaluation Understudy)
- 예측한 답과 ground-truth 사이의 precision
- BLEU-n ⇒ uniform n-gram weight . n-gram끼리 겹치는 비율 계산
2. Unicode & Tokenization
1) Unicode
- 전 세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋
- 각 문자마다 숫자 하나에 매핑
UTF-8 (Unicode Transformation Format)
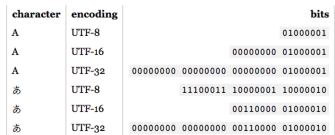
- 현재 가장 많이 쓰는 인코딩 방식
- 문자 타입에 따라 다른 길이의 바이트 할당
- Python에서 Unicode 다루기
- ord : 문자를 유니코드 로 변환
- chr : 유니코드를 문자로 변환
Unicode와 한국어

- 한국어는 한자 다음으로 유니코드에서 많은 코드를 차지하고 있는 문자
- 완성형
- 현대 한국어의 자모 조합으로 나타낼 수 있는 모든 완성형 한글 11,172자(가, 각, …, , ) (U+AC00 ~ U+D7A3)
- 조합형
- 조합하여글자를만들수있는 초·중·종성 (U+1100 ~ U+11FF, U+A960 ~ U+A97F, U+D7B0 ~ U+D7FF)
2) Tokenizing
- 텍스트를 token 단위로 나누는 것
- 단어(띄어쓰기 기준), 형태소, subword 등 여러 토큰 기준이 사용됨
Subword Tokenizing

- 자주 쓰이는 글자 조합은 한 단위로 취급하고, 자주 쓰이지 않는 조합은 subword로 쪼갬
- corpus에 자주 등장하는 단어 순으로 단어화 진행
- ## 디코딩을 할 때 앞 토큰에 띄어쓰기 없이 붙임. 원래 문장 복원 용이
BPE (Byte-Pair Encoding)
- 빈도수에 기반해 단어를 의미 있는 패턴(Subword)으로 잘라서 tokenizing
- 데이터 압축용으로 제안된 알고리즘
- NLP에서 토크나이징용으로 활발히 사용됨
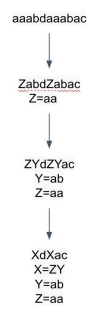
- 과정
- 가장 자주 나오는 글자 단위 Bigram (or Byte pair)를 다른 글자로 치환
- 치환된 글자를 저장
- 1~2번 반복
3. KorQuAD 살펴보기
3. 1. KorQuAD (Korean Question Answering Dataset)
LG CNS가 AI 언어지능 연구를 위해 공개한 질의응답/기계독해 한국어데이터셋 인공지능이 한국어 질문에 대한 답변을 하도록 필요한 학습 데이터셋
- 1,550개의 위키피디아 문서에 대해서 10,649 건의하위 문서들과 크라우드소싱을 통해 제작한 63,952 개의 질의응답 쌍으로 구성되어 있음(TRAIN 60,407 / DEV 5,774 / TEST 3,898)
- 누구나 데이터를 내려받고, 학습한 모델을 제출하고 공개된 리더보드에 평가를 받을 수 있음 → 객관적인 기준을 가진연구결과 공유가 가능해짐
- 현재v1.0, v2.0 공개: 2.0은 보다 긴 분량의 문서가 포함, 단순히 자연어 문장 뿐 아니라 복잡한 표와 리스트 등을 포함하는 HTML 형태로 표현되어 있어 문서 전체 구조에 대한 이해가 필요
3. 2. KorQuAD 데이터 수집 과정

SQuAD v1.0의 데이터 수집 방식을 벤치마크하여 표준성을 확보함
3. 3. HuggingFace datasets 라이브러리 활용
from datasets import load_dataset
dataset = load_dataset('squad_kor_v1', split='train')3. 4. KorQuAD 예시


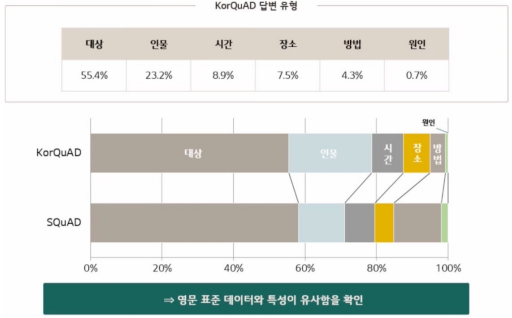
3. 5. KorQuAD 통계치

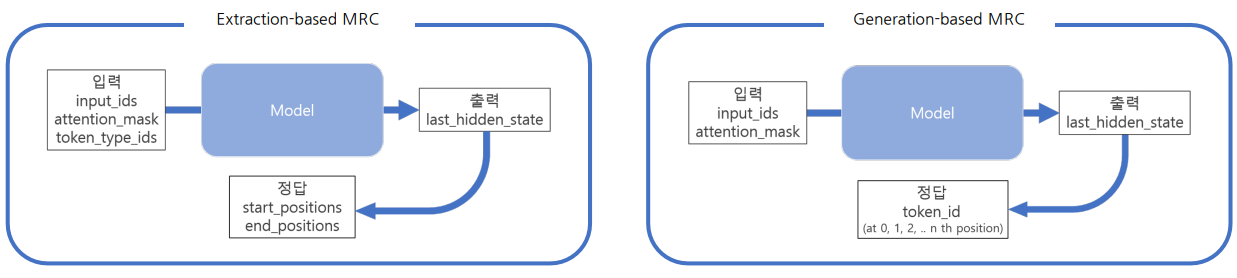
4. Extraction-based MRC
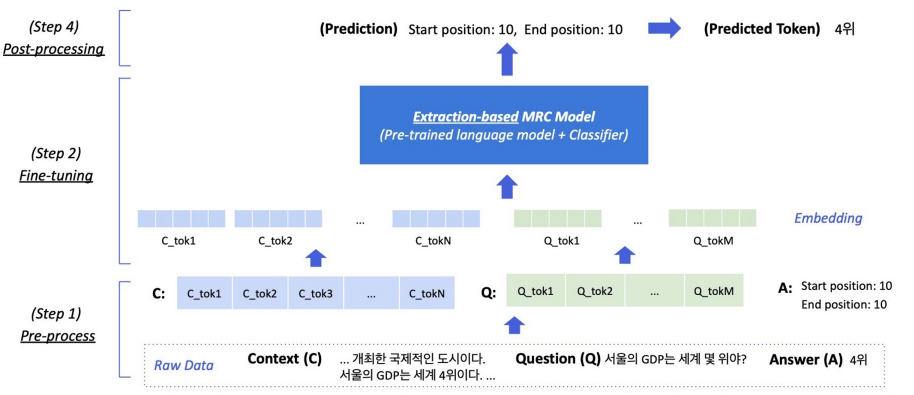
- 모델 구조: PLM + Classifier
- 문제 유형: 지문(context) 내 답의 위치를 예측. 분류 문제
- Loss 계산을 위한 답(Prediction)의 형태: 지문 내 답의 위치
- 시작과 끝에 해당하는 contextualized vector(embedding)를 scalar value로 내보냄
- scalar value가 가장 높은 시작/끝 값을 찾은 후 이에 해당하는 span이 최종 예측 답변
4. 1. Pre-processing
Input

Tokenization
- 텍스트를 작은 단위(Token)로 나누는 것
- 최근엔 OOV 문제를 해결해주고 정보학적으로 이점을 가진 Byte Pair Encoding(BPE)을 주로 사용함
- 본강에선 BPE 방법론 중 하나인 Wordpiece Tokenizer를 사용
- WordPiece Tokenizer 사용 예시
- “미국 군대 내 두번째로 높은 직위는 무엇인가?”
- [’미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, ‘높은’, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
Special Tokens

Attention mask

- 입력 sequence 중 attention을 연산할 때 무시할 토큰을 표시하기 위해 사용
- 0 - 무시, 1 - 무시 X
- 보통 [PAD]와 같은 의미 없는 Special Token을 무시하기 위해 사용
Token type ids
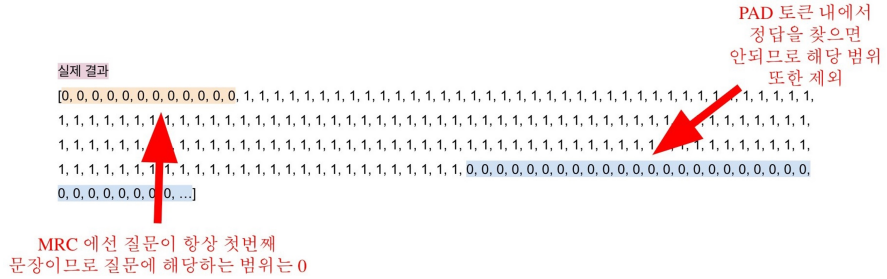
- 입력이 2개 이상의 sequence일 때, 각각에게 id를 부여하여 모델이 구분해서 해석하도록 유도
Output

- 정답은 문서내 존재하는 연속된 단어토큰 (span)이므로, span의 시작과 끝 위치를 알면 정답을 맞출 수 있
- Extraction-based에선 답안을 생성하기보다 시작 위치와 끝 위치를 예측하도록 학습함
- 원래 text에 해당하는 token들을 찾을 수 있어야 함
- 가장 간단한 방법: 해당 text를 포함하는 모든 단어를 가져와서 시작과 끝 표시
4. 2. Fine-tuning
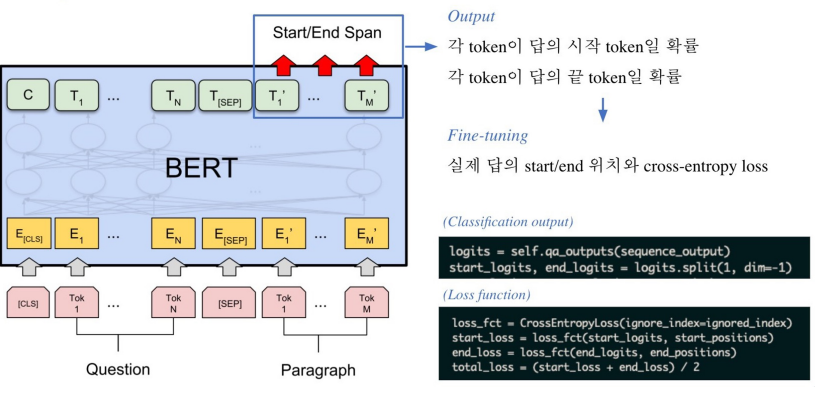
- 정답에 해당되는 각 임베딩을 linear transformation을 통해 각 단어마다 하나의 숫자(=점수) 를 출력
- 위와 같은 점수 기준으로 시작 위치와 끝 위치를 구함
- 정답은 문서내 존재하는 연속된 단어 토큰(span)이므로 span의 시작과 끝 위치를 알면 정답을 맞출 수 있음
4. 3. Post-processing
1) 불가능한 답 제거
- End position이 Start Position보다 앞에 있는 경우
- 예측한 위치가 context를 벗어난 경우 (e.g. question 위치쪽에 답이 나온 경우)
- 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
2) 최적의 답안 찾기
- Start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾음
- 불가능한 start/end 조합을 제거함
- 가능한 조합들을 score의 합이 큰 순서대로 정렬함
- Score가 가장 큰 조합을 최종 예측으로 선정함
- Top-k가 필요한 경우 차례대로 내보냄
5. Generation-based MRC
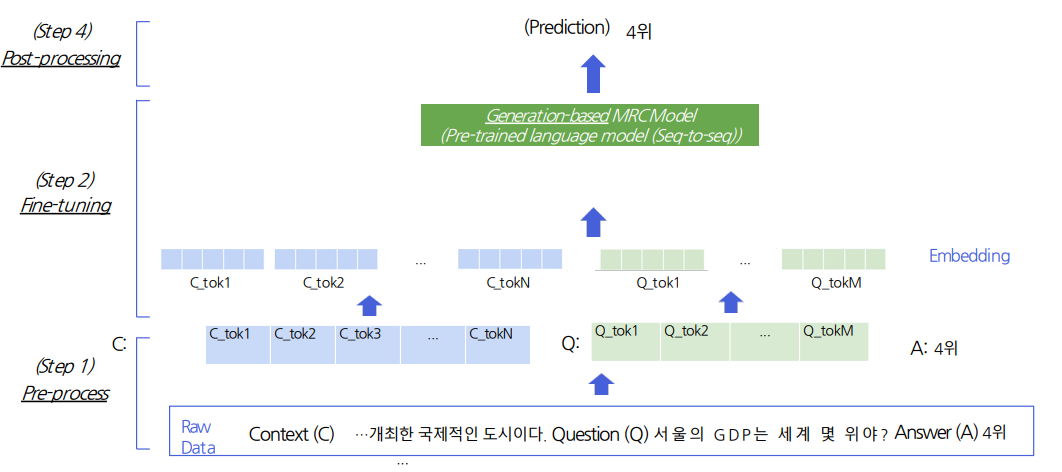
- 모델 구조: Seq2Seq PLM 구조
- 모든 pre-trained LM이 seq2seq을 할 수 있는 건 X
- BERT → encoding 단계만 있고 decoding 단계는 없으므로 Generation-based MRC에 활용 불가
- text를 decoding할 때 teacher forcing 같은 방식으로 학습
- 문제 유형: 주어진 지문과 질의를 보고 답변 생성. 생성 문제
- Loss 계산을 위한 답(Prediction)의 형태: Free-form text 형태
5. 1. Pre-processing
Input

Special Token
- 학습 시에만 사용되며 단어 자체의 의미는 가지지 않는 특별한 토큰
- SOS(StartOfSentence),EOS(EndOfSentence), CLS, SEP, PAD, UNK ... 등
- Extraction-based MRC에선 CLS, SEP, PAD 토큰 사용
- Generation-based MRC에서도 PAD 토큰은 사용. CLS, SEP 토큰도 사용은 가능하나 자연어를 이용하여 정해진 텍스트 포맷으로 데이터를 생성함
Additional Information
Attention mask
- Extraction-based MRC와 똑같이 어텐션 연산을 수행할 지 결정하는 어텐션 마스크 존재
Token type ids
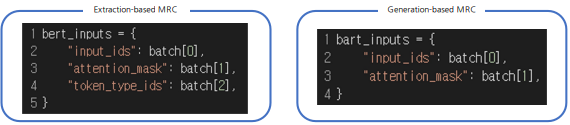
- BERT와 달리 BART 에선 입력 시퀀스에 대한 구분이 없어 token_type_ids가 존재 X
- [SEP] 토큰이 있으면 token type id는 직접적으로 제공되지 않아도 어느 정도 모델이 구분 가능함
- 초창기에는 직접적으로 구분해주려 했지만 점점 크게 중요하지 않다고 판단되어 token type ids를 input에서 뺀 모델들이 있음
Output
Sequence of token ids
- Extraction-based MRC는 정답의 위치를 정확히 특정해야 했는데 Generation-based MRC는 그럴 필요 X → 정답 그대로 넘겨주면 됨
- 전체 sequence의 각 위치마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 분류 문제
5. 2. Post-processing
Decoding
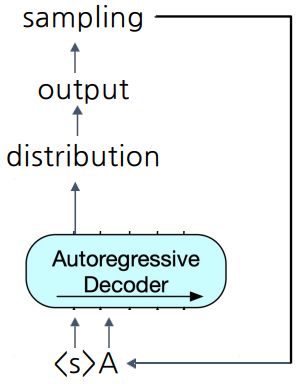
- autoregressive 디코더에서 이전 스텝에서 나온 출력이 다음 스텝의 입력으로 들어감
- 맨 처음 입력 = 문장 시작을 뜻하는 스페셜 토큰
Searching
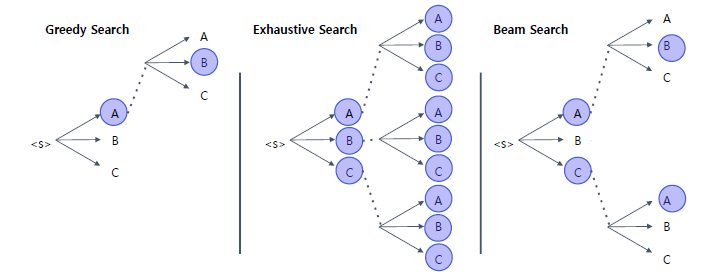
- Greedy Search: decision making을 early stage에서 하므로 초반에 틀리면 다 틀릴 지도 모른다는 단점
- Exhaustive Search: 모든 가능성을 다 봄 → 가능한 가짓수가 time step에 비례하므로 문장이 조금만 길어져도, vocab size가 조금만 커져도 불가능
- Beam Search: exhausitve search를 하되, 각 time step마다 가장 점수가 높은 top-k만 유지 → 가장 많이 쓰는 방식
6. BART
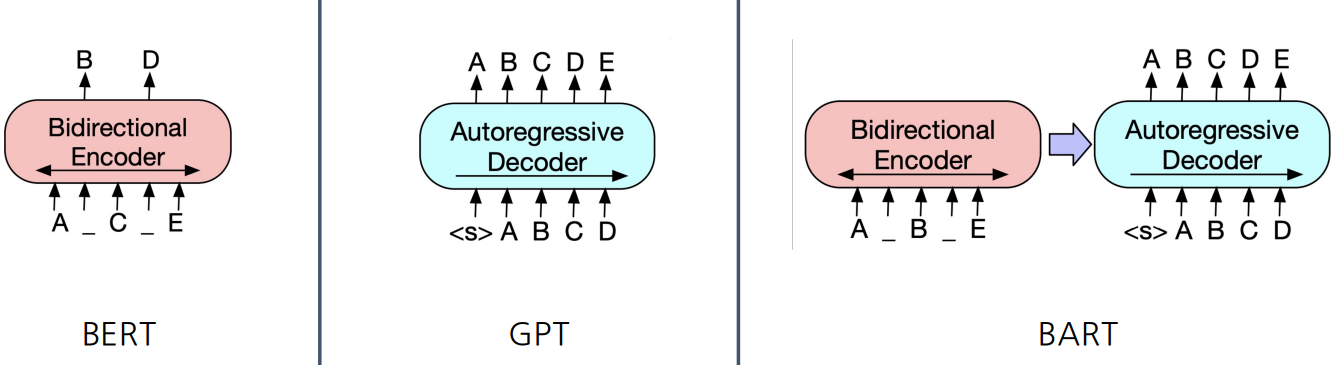
기계 독해, 기계 번역, 요약, 대화 등 Seq2Seq 문제의 pre-training을 위한 denoising autoencoder
- denoising autoencoder: 텍스트에 Noise를 인위적으로 주입하고 Noise가 없는 원래 버전을 reconstruct
BART Encoder & Decoder
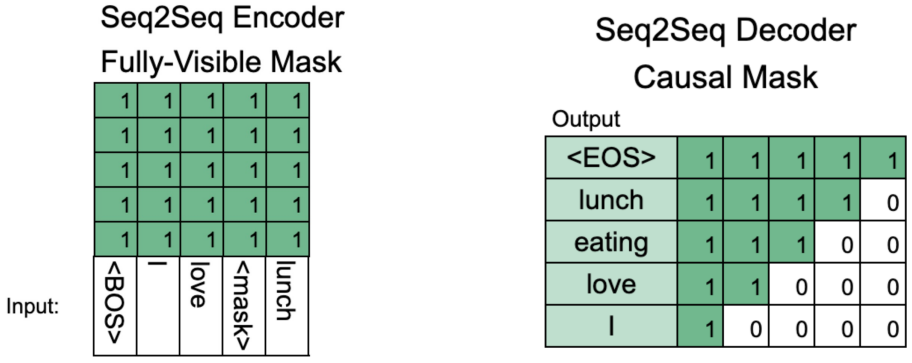
- Encoder: BERT 처럼 bi-directional
- Decoder: GPT 처럼 uni-directional (autoregressive)
Pre-training BART
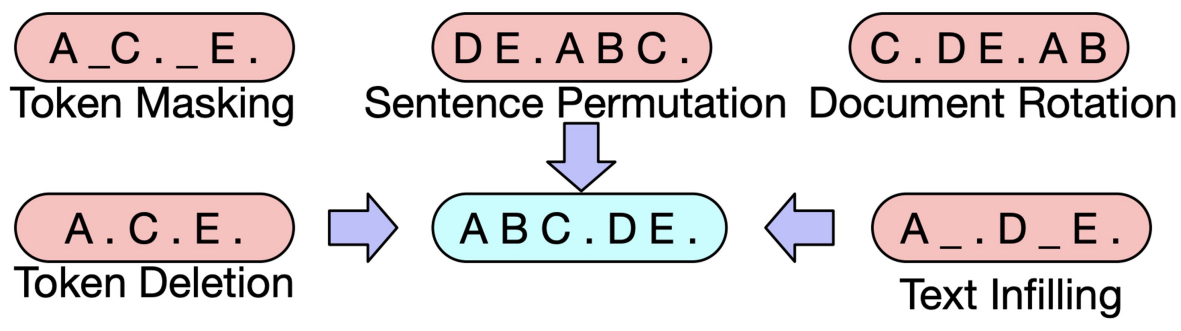
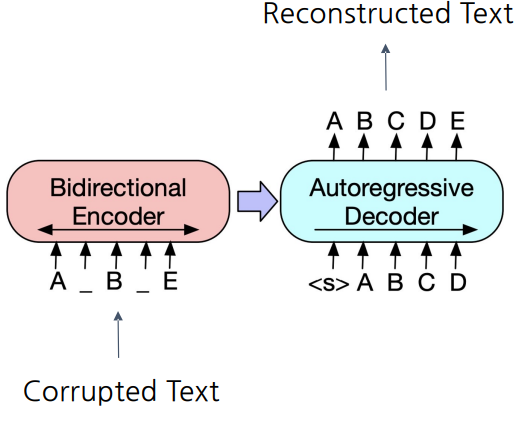
- BART는 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는것으로 pre-training함
출처: 네이버 커넥트재단 부스트캠프 AI Tech

