
1. Passage Retrieval(문서 검색)
질문(query)에 맞는 문서(passage)를 찾는 것
Passage Retrieval with MRC

- Open-domain Question Answering: 대규모의 문서 중에서 질문에 대한 답을 찾기
- Passage Retrieval과 MRC를 이어서 2-Stage로 만들 수 있음

- Query와 Passage를 임베딩한 뒤 유사도로 랭킹을 매기고, 유사도가 가장 높은 Passage를 선택함
1. 1. Passage(구절) Embedding
구절(Passage)을 벡터로 변환하는 것
Passage Embedding Space
- Passage Embedding의 벡터 공간.
- 벡터화된 Passage를 이용하여 Passage 간 유사도 등을 알고리즘으로 계산할 수 있음
2. Sparse Embedding
- BoW를 구성하는 n-gram 방식
- Term이 document에 등장하는지
- Term이 몇번 등장하는지 (e.g. TF-IDF)
2. 1. Sparse Embedding 특징
- Dimension of embedding vector = number of terms
- 등장하는 단어가 많아질수록 증가
- N-gram의 n이 커질수록 증가
- Term overlap을 정확하게 잡아 내야 할 때 유용
- 의미(semantic)가 비슷하지만 다른 단어인 경우 비교가 불가 (-> Dense Embedding 활용)
2. 2. TF-IDF(Term Frequency Inverse Document Frequency)

문서 내에 단어가 자주 등장하지만 다른 문서에는 단어가 등장하지 않을 때, 단어를 중요하다고 판단 점수를 더 주는 방식
Term Frequency (TF)
해당 문서 내 단어의 등장 빈도 count
- 각 단어별 등장 횟수를 count
- Normalize by count 횟수를 문서 내 등장한 총 단어 개수로 나눠줌
- raw count / total # of words
Inverse Document Frequency (IDF)
단어가 제공하는 정보의 양

- Document Frequency(DF): Term t가 등장한 document의 개수
- N: 총 document의 개수
2. 2. BM25

TF-IDF의 개념을 바탕으로 문서의 길이까지 고려하여 점수를 매김
- TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 함
- 평균적인 문서 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치 부여
- 실제 검색엔진, 추천 시스템 등에서 아직까지 많이 사용됨
3. Dense Embedding

Sparse Embedding의 한계
1. 차원의 수가 매우 크다(compressed format으로 극복 가능)
2. 단어의 유사성을 고려하지 못함
3. 1. Dense Embedding 특징
- Sparse representation의 단점을 보완
- 더 작은 차원의 고밀도 벡터 (length=50~1000)
- 각 차원이 특정 term에 대응되지 않음
- 대부분의 요소 값이 0이 아님
- 최근 사전학습 모델의 등장, 검색 기술의 발전 등으로 인해 Dense Embedding 활발히 사용
Overview of Passage Retrieval with Dense Embedding
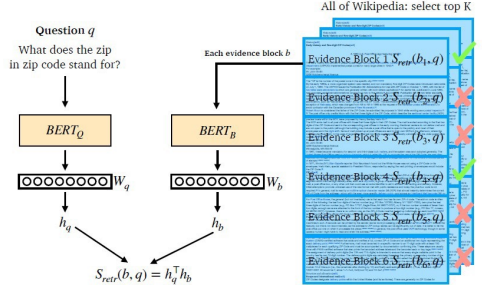
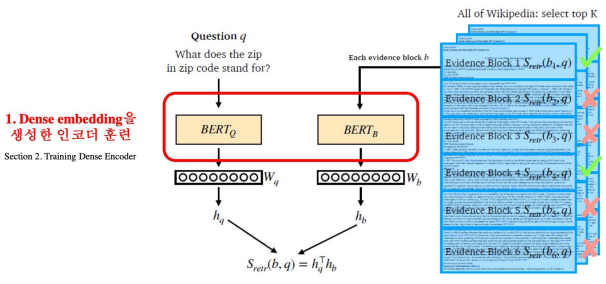
3. 2. Training Dense Encoder
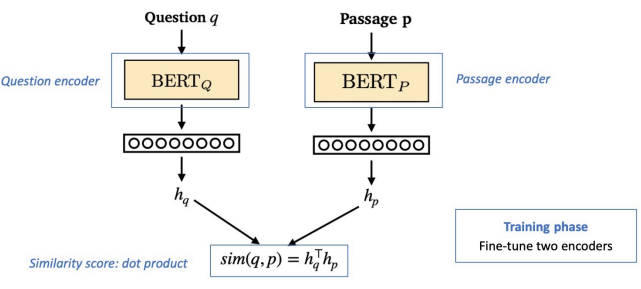
BERT와 같은 다양한 Pre-trained Language Model이 자주 사용됨
- MRC와 차이점: MRC는 Passage와 Question 함께 input으로 넣어줬지만, Dense Encoder의 경우 각각에 대한 embedding을 구하고 싶으므로 독립적으로 넣어줌
[CLS] token의 output 사용
- MRC와 차이점: MRC는 각 토큰 별로 score를 내는 것이 목적이었지만, Dense Encoder의 경우 embedding을 구하는 것이 목적이므로 [CLS] token의 output만 구함
- Passage, Question 둘 다 위와 같은 방식으로 인코딩 → 같은/다른 파라미터를 사용할 지는 개인의 선택
Dense Encoder의 학습 목표와 학습 데이터
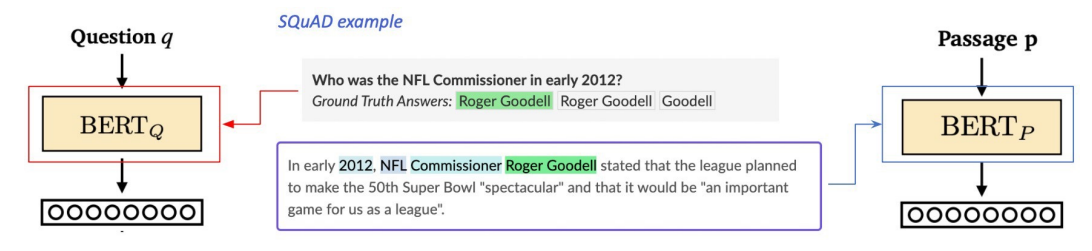
- 학습 목표: 연관된 Question과 Passage dense embedding 간의 거리를 좁히는 것 (= inner product를 높이는 것)
- Vector 공간에서 Nearest Neighbor Search
- Inner product space에서 highest dot product score
- 정답일 경우 유사도가 높도록, 아닐 경우 낮도록 BERT를 학습시킴
- Challenge: 연관된 Question과 Passage를 어떻게 찾을 것인가?
Negative Sampling
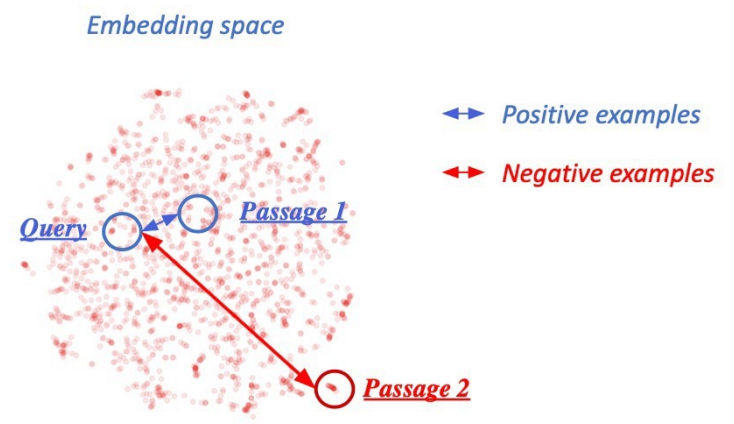
- 연관된 Question과 Passage 간의 dense embedding 거리는 좁힘 → Positive
- 연관되지 않은 Question과 Passage 간의 dense embedding 거리는 멀게 함 → Negative
- 어떻게 Negative Example들을 뽑을 수 있을까?
- Corpus 내에서 랜덤하게
- 좀 더 헷갈리게 (ex) 높은 TF-IDF 스코어를 가지지만 정답은 포함하지 않는 샘플)
Objective Function

- Positive passage 에 대한 negative log likelihood (NLL) loss
Evaluation Metric
- Top-k retrieval accuracy : retrieved passage 중 답(최종 MRC의 output)을 포함하는 passage의 비율
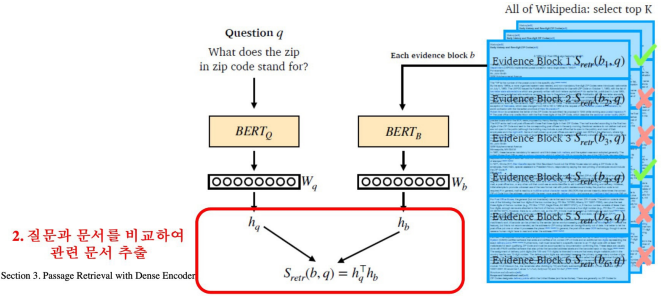
3. 3. Passage Retrieval with Dense Encoder
From dense encoding to retrieval
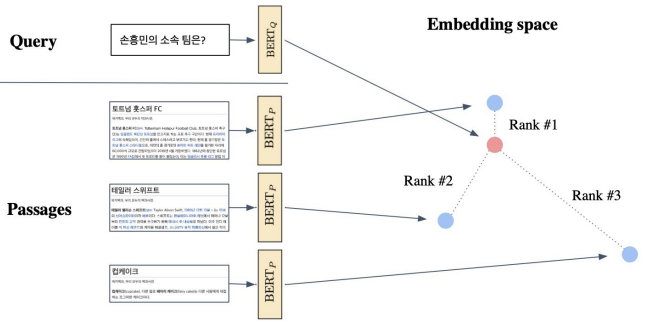
- Inference: Passage와 Query를 각각 embeding한 후, Query로부터 가까운 순서대로 Passage의 순위를 매김
From retrieval to open-domain question answering
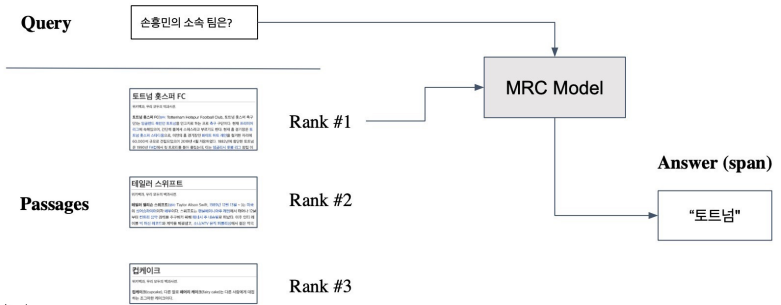
- Retriever을 통해 찾아낸 Passage를 활용 → MRC 모델로 답을 찾음
How to make better dense encoding
- 학습 방법 개선 (e.g. DPR)
- 인코더 모델 개선 ex) BERT보다 큰, 정확한 Pretrained 모델
- 데이터 개선 ex) 더 많은 데이터, 전처리 등
4. Scaling up with FAISS
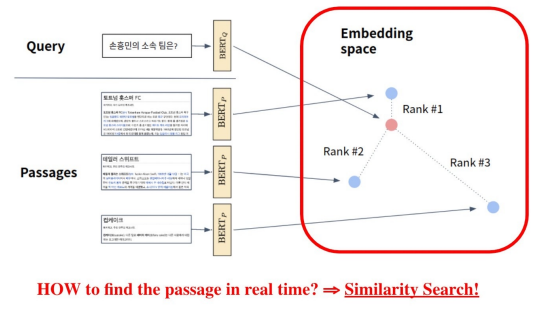
Passage Retrieval and Similarity Search
데이터의 크기를 키울 경우(Scaling up) 고려해야할 것이 많다. Embedding Space의 유사한 Passage 벡터가 많아질 경우 어떻게 효율적으로 가장 가까운 벡터를 찾을 수 있을까?
4. 1. MIPS (Maximum Inner Product Search)

- Brute-force search
- 저장해 둔 모든 Sparse/Dense 임베딩에 대해 일일히 내적값을 계산하여 가장 값이 큰 passage 추출
- 문서의 양이 많아질 수록 비효율적
- Nearest Neighbor Search 보다 Inner Product Search가 많이 쓰이고 있음
- 효율성을 고려해보면 L2 distance를 재는 것보다 Dot product를 계산하여 최댓값을 찾는 문제로 보는 것이 더 좋음
MIPS in Passage Retrieval
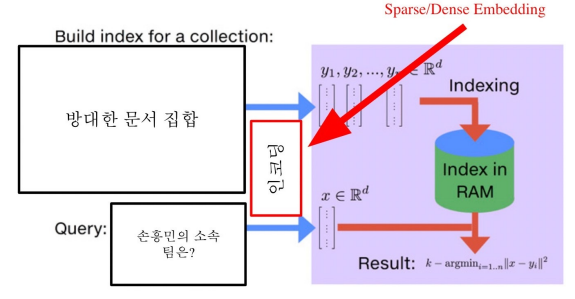
MIPS & Challenges
실제로 검색해야 할 데이터는 훨씬 방대함
- 위키피디아 5백만 개, 수십 억, 조 단위까지 커질 수 있음
-> 모든 문서 임베딩을 일일히 보면서(Brute-force 방식) 검색할 수 없음
Tradeoffs of Similarity Search
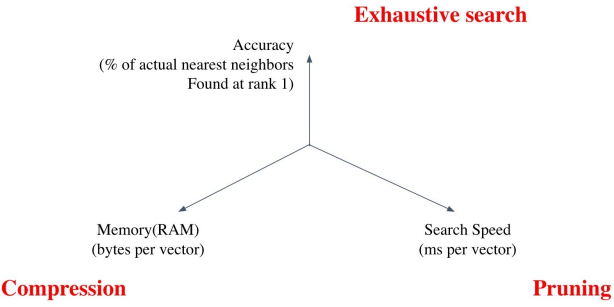
1) Search Speed
- 쿼리 당 유사한 벡터를 k개 찾는 데 얼마나 걸리는가
- 가지고 있는 벡터량이 클 수록 더 오래 걸림
2) Memory Usage
- 벡터를 사용할 때 어디서 가져올 것인가
- RAM에 모두 올려두면 빠르긴 하지만 많은 RAM 용량을 요구함
- 디스크에서 불러와야 한다면 속도가 느려짐
3) Accuracy
- Brute-force 검색 결과와 얼마나 비슷한가
- 속도를 증가시키려면 정확도를 희생해야 하는 경우가 많음
속도(search time)와 재현율(recall)의 관계
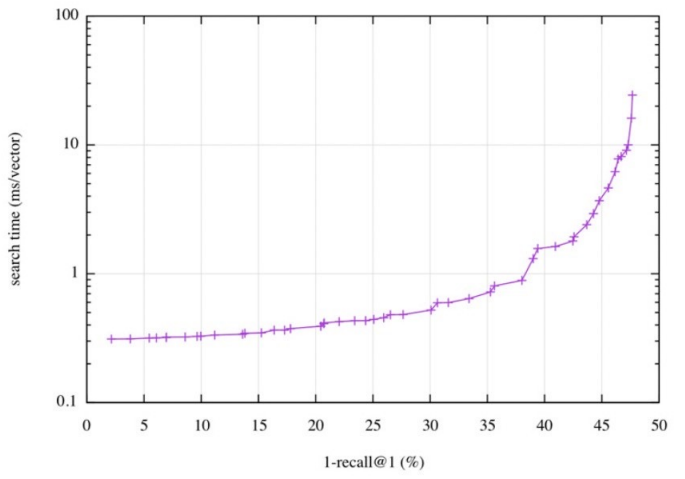
- 더 정확한 검색을 하려면 더 오랜 시간이 소요됨
코퍼스(corpus)의 크기가 커질 수록
- 탐색 공간이 커지고 검색이 어려워짐
- 저장해 둘 Memory space 또한 많이 요구됨
- Sparse Embedding의 경우 이러한 문제가 훨씬 심함
4. 2. Approximating Similarity Search
1) Scalar Quantization (SQ)
Compression: vector를 압축해 하나의 vector가 적은 용량을 차지 ⇒ 압축량 ↑ ⇒ 메모리 ↓ 정보 손실 ↑
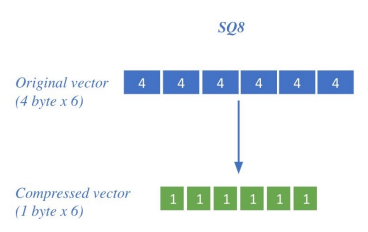
ex) 4-byte floating point ⇒ 1-byte unsigned integer로 압축
- Inner product search를 하는 경우, 4 byte까지 필요한 경우가 많지 않음 → 1 byte로 해도 정확한 경우 多
2) Inverted File (IVF)
Pruning 기법: Search space를 줄여 search 속도를 개선시킬 수 있음 (dataset의 subset만 방문)
- 점들을 정해진 클러스터에 소속시켜서 군집을 만듦
- 쿼리가 들어왔을 때, 쿼리와 근접한 클러스터들만 확인하는 방식
- 근접한 클러스트 내에선 Exhaustive search로 다 확인
1. Clustering
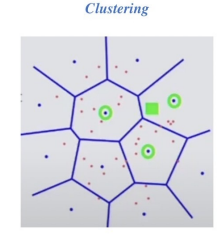
- 전체 vector space를 k 개의 cluster로 나눔 (ex. k-means clustering)
2. Inverted file (IVF)
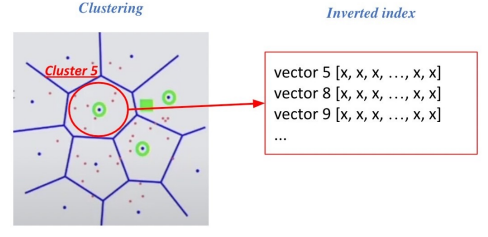
- Vector의 index = inverted list structure
- 각 cluster의 centroid id와 해당 cluster의 vector들이 연결되어 있는 형태
3. Searching with clustering & IVF
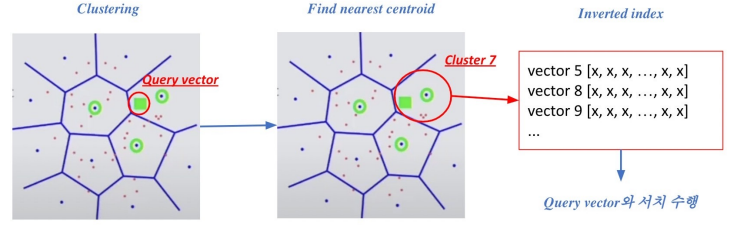
- 주어진 Query 벡터에 대한 근접한 centroid 벡터를 찾음
- 찾은 cluster의 inverted list 내 vector들에 대해 서치 수행
4. 3. FAISS
Faiss is a library for efficient similarity search and clustering of dense vectors.
- Indexing 부분에 도움을 주기 위한 것 (encoding 부분관 상관 X)
1) Pssage Retrieval with FAISS
Train index & map vectors
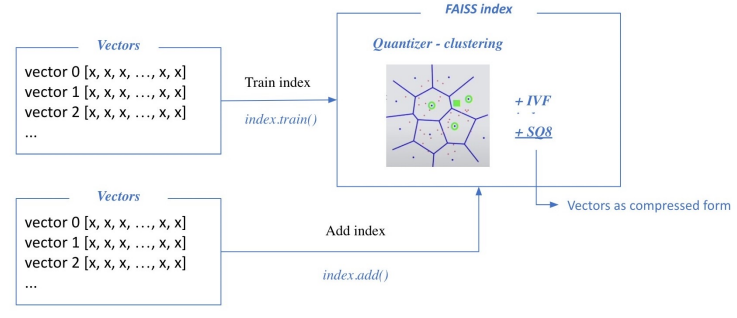
- 학습 단계가 선행되는 이유
- 효율적인 클러스터 확보
- SQ 과정에서 float number들에 대한 파악 (max, min이 얼마인지, 얼마로 scale하고 얼만큼 offset할 것인지)
- 학습 단계를 통해 클러스터랑 SQ 파일 정의가 끝나면 실제 클러스터와 벡터들을 투입
- 대부분의 경우, 학습 데이터와 더하는 데이터를 따로하진 않음
- 따로 하는 경우는 보통 더해야 할 데이터가 너무 많아서 이 데이터들을 전부 학습하는 게 비효율적일 때
- 더해야할 데이터의 일부를 샘플링해서 학습 데이터로 활용
Search based on FAISS index
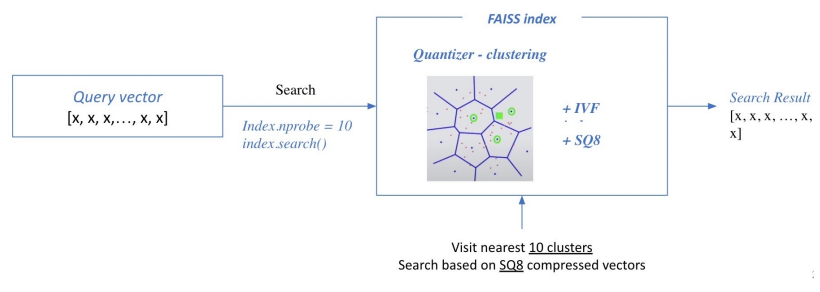
- Query와 가장 근접한 클러스트를 찾고 클러스트 내에 있는 벡터들을 Exhaustive search해서 가장 유사한 top-k개의 벡터를 찾아냄
2) FAISS Basics
Brute-force로 모든 벡터와 쿼리를 비교하는 가장 단순한 인덱스 만들기
준비하기
d = 63 # 벡터의 차원
nb = 100000 # 데이터베이스의 크기
nq = 10000 # 쿼리 개수
xb = np.random.random((nb, d)).astype('float32') # 데이터 베이스 예시
xq = np.random.random((nq, d)).astype('float32') # 쿼리 예시인덱스 만들기
index = faiss.IndexFlatL2(d) # 인덱스 빌드하기
index.add(xb) # 인덱스에 벡터 추가하기검색하기
k = 4 # 가장 가까운 벡터 4개를 찾고 싶음
D, I = index.search(xq,k) # 검색하기
# D: 쿼리와의 거리
# I: 검색된 벡터의 인덱스

